Ceph Crash Recovery
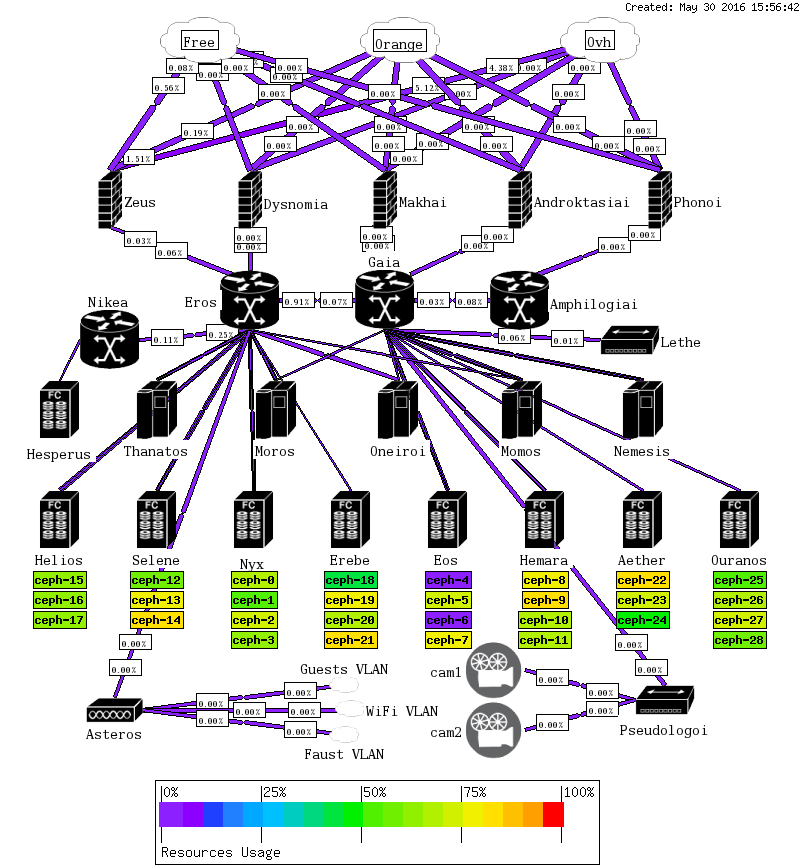
Today we will see the steps to replace a Ceph node, including the MON, MGR, MDS and OSD services.
While I would usually try to salvage the disks from a failing node, sometimes using dd conv=noerror,sync iflag=fullblock dumping a filesystem from a disk ignoring IO errors, others using a disk duplication devices: today I am unable to salvage my node filesystem, we would see the steps to re-deploy a new host from scratch.
Redeploy Hypervisor
Starting from new drives, I reinstalled my physical server, using a local PXE. Using puppet, the server is then configured as a KVM hypervisor, and automount gives me access to my KVM models. I would next deploy a CentOS 8 guest, re-using the FQDN and IP address from my previous Ceph node.
Ceph MON
I would start by installing EPEL and Ceph repositories – matching my Ceph release, Octopus. Update the system, as my CentOS KVM template dates back from 8.1. Reboot. Then, we would install Ceph packages:
dnf install -y ceph-osd python3-ceph-common ceph-mon ceph-mgr ceph-mds ceph-base python3-cephfs
For simplicity, we would disable SELinux and firewalling – matching my other nodes configuration, though this may not be recommended in general. Next, we would retrieve Ceph configuration out of a surviving MON node:
scp -rp mon1:/etc/ceph /etc/
Confirm that we can now query the cluster, and fetch the Ceph mon. keyring:
ceph osd tree
ceph auth get mon. -o /tmp/keyring
ceph mon getmap -o /tmp/monmap
Having those, you may now re-create your MON, re-using its previous ID (in my case, mon3)
mkdir /var/lib/ceph/mon/ceph-mon3
ceph-mon -i mon3 –mkfs –monmap /tmp/monmap –keyring /tmp/keyring
chown -R ceph:ceph /var/lib/ceph/mon/ceph-mon3
Next, re-create the systemd unit starting Ceph MON daemon:
mkdir /etc/systemd/system/ceph-mon.target.wants/
cd /etc/systemd/system/ceph-mon.target.wants/
ln -sf /usr/lib/systemd/system/ceph-mon\@.service ceph-mon\@mon3.service
systemctl daemon-reload
systemctl start ceph-mon@mon3.service
journalctl -u ceph-mon@mon3.service
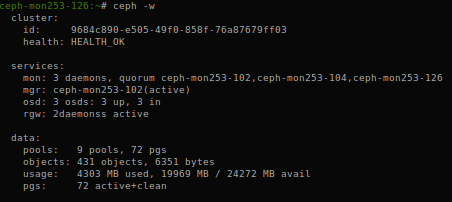
ceph -s
At that stage, we should be able to see the third monitor re-joined our cluster.
Ceph OSDs
The next step would be to re-deploy our OSDs. Note that, at that stage, we should be able to re-import our existing OSD devices, assuming they were not affected by the outage. Here, I would also proceed with fresh drives (logical volumes on my hypervisor).
Let’s fetch the osd bootstrap key (could be done with ceph auth get, as for the mon. key above) and prepare the directories for my OSDs (IDs 1 and 7)
scp -p mon1:/var/lib/ceph/bootstrap-osd/ceph.keyring /var/lib/ceph/bootstrap-osd/
mkdir -p /var/lib/ceph/osd/ceph-1 /var/lib/ceph/osd/ceph-7
chown -R ceph:ceph /var/lib/ceph/bootstrap-osd /var/lib/ceph/osd
Next, I would re-create my first OSD:
ceph osd out osd.7
ceph osd destroy 7
ceph osd destroy 7 –yes-i-really-mean-it
ceph-volume lvm zap /dev/vdb
ceph-volume lvm prepare –osd-id 7 –data /dev/vdb
ceph-volume lvm activate –all
ceph osd tree
ceph -s
We should be able to confirm the OSD 7 is back up, and that Ceph is now re-balancing data. Let’s finish with the second OSD I need to recover, following the same process:
ceph osd out osd.1
ceph osd destroy 1
ceph osd destroy 1 –yes-i-really-mean-it
ceph-volume lvm zap /dev/vdc
ceph-volume lvm prepare –osd-id 1 –data /dev/vdc
ceph-volume lvm activate –all
ceph osd tree
ceph -s
At that stage, the most critical part is done. Considering I am running on commodity hardware, VMs on old HP Micro Servers with barely 6G RAM and a couple CPUs, I’ve left Ceph alone for something like 12 hours, to avoid wasting resources with MDS and MGR daemons that are not strictly mandatory.
Ceph MGR
My data being pretty much all re-balanced, no more degraded or undersized PGs, I eventually redeployed the MGR service:
mkdir /var/lib/ceph/mgr/ceph-mon3
ceph auth get mgr.mon3 -o /var/lib/ceph/mgr/ceph-mon3/keyring
chown -R ceph:ceph /var/lib/ceph/mgr
mkdir ceph-mgr.target.wants
cd ceph-mgr.target.wants
ln -sf /usr/lib/systemd/system/ceph-mgr\@.service ceph-mgr\@mon3.service
systemctl daemon-reload
systemctl start ceph-mgr@mon3
ceph -s
Ceph MDS
Next, as I’m using CephFS with my Kubernetes clusters, I would need to recreate my third MDS. The process is pretty similar to that of deploying a MGR:
mkdir /var/lib/ceph/mds/ceph-mon3
ceph auth get mds.mon3 -o /var/lib/ceph/mds/ceph-mon3/keyring
chown -R ceph:ceph /var/lib/ceph/mds
mkdir ceph-mds.target.wants
cd ceph-mds.target.wants
ln -sf /usr/lib/systemd/system/ceph-mds\@.service ceph-mds\@mon3.service
systemctl daemon-reload
systemctl start ceph-mds@mon3
ceph -s
Finishing up
In my case, I’ve also installed and configured NRPE probes.
Note that I did not cover the topic of re-deploying RadosGW: in my case, with limited resources on my Ceph nodes, my RGW daemons are deployed as containers, in Kubernetes. My workloads that require s3 storage may then use Kubernetes local Services and Secrets with pre-provisioned radosgw user credentials.
Obviously I could have used ceph-ansible redeploying my node. Though there’s more fun in knowing how it works behind the curtain. I would mostly use ceph-ansible deploying clusters, with customers — mine was last deployed a couple years ago.
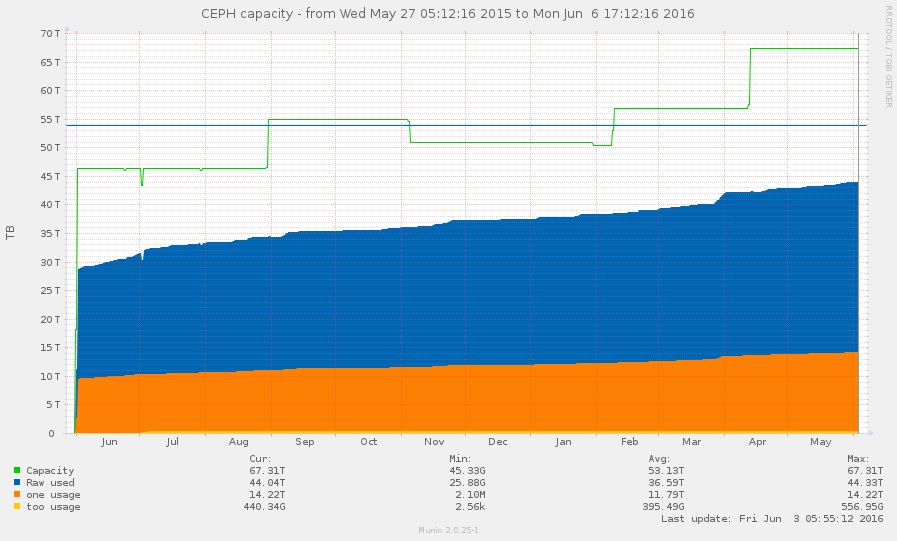
The time going from an installed CentOS to a fully recovered Ceph node is pretty amazing. No more than one hour re-creating Ceph daemons, a little over 12h watching objects being recovered and re-balanced — for over 2Tb of data / 5T raw, and again: old and low quality hardware, when compared with what we would deal with IRL.
From its first stable release, in early 2010s, to the product we have today, Ceph is a undeniably a success story in the Open Sources ecosytem. Haven’t seen a corruption I couldn’t easily fix in years, low maintenance cost, still runs fairly well on commodity hardware. And all that despite of RedHat usual fuckery.