Netdata
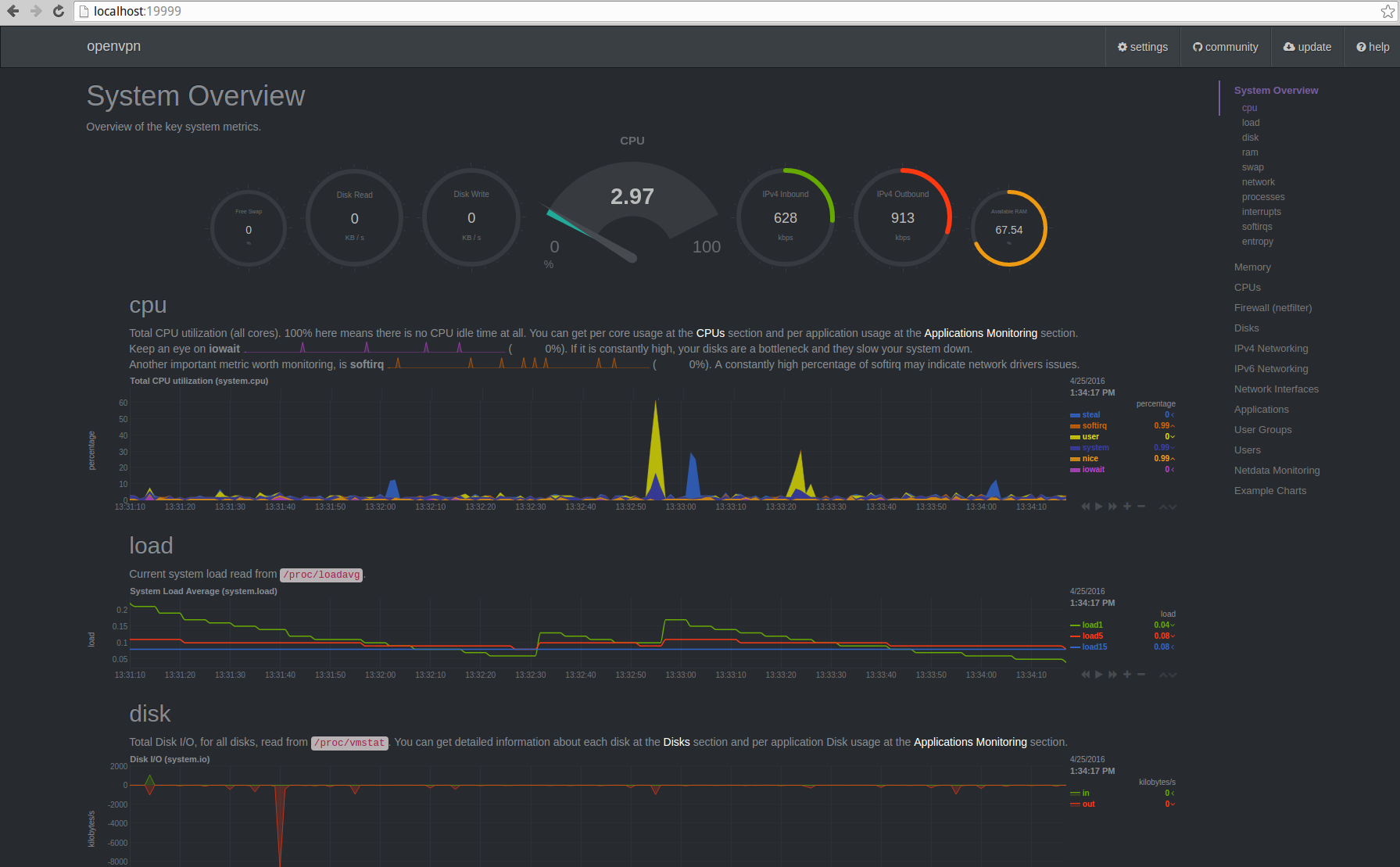
Netdata Dashboard
Lately, a friend advised me to give a look to Netdata. On paper, a lightweight dashboard, written in C, providing with realtime performances monitoring of Linux servers. Demo available here and there.
Having read the repository readme and installation instructions, the next thing I did to familiarize myself with Netdata, is to review the currently opened issues and pull requests. I can see FreeBSD is being investigated upon, packages are on their way, security concerns (such as Netdata default listen address) are being addressed, … Netdata may not be completely ready, yet it’s safe enough to be run pretty much everywhere, and definitely worth giving it a shot.
The setup process is pretty easy. You’ll pull a few dependencies – the kind you may not want on a production server though. A shell script will then build and install everything. A debian package skeleton is already there, if you prefer distributing binaries. Note that so far, you will have to register netdata service yourself, although their repository already includesboth systemd and initd samples.
As of right now, Netdata default behavior would be to listen on all your interfaces.
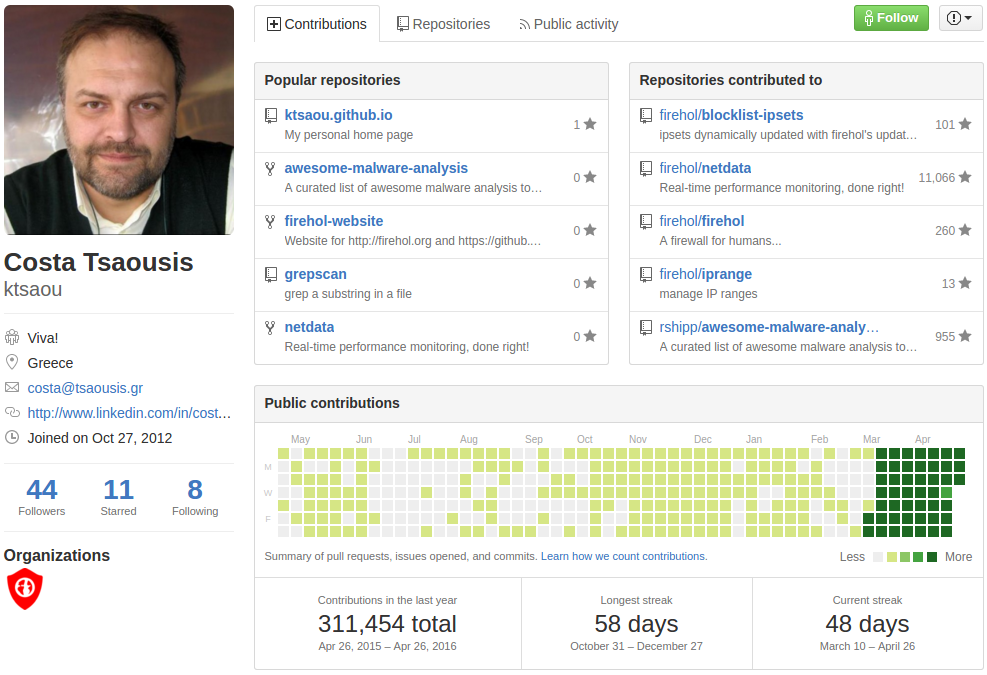
Netdata Author profile on Github
One last detail that caught my eye is that issue, enlightening the kind of guy we’re dealing with.
And I should probably also mention his GitHub profile, with the most amazing stats you’ll ever see, showing the kind of activity there’s been around Netdata lately.
One thing Netdata does not intend to provide is everlasting histories, nor even metrics aggregation. A couple issues tell about collectd or statsd potential integrations. Although Netdata intends to perform with very little overhead (contrarily to tools such as Collectd, which may increase your disk IOs) while displaying instantaneous values as and when they are read (contrarily to tools such as Munin, which won’t pull metrics faster than one dot per minute, and may need additional time generating its graphs).
Netdata probably won’t replace any of your existing service watching over your system metrics, yet it is indubitably powerful, pretty well written, while offering an exhaustive view over your system.