Reweighting Ceph
For those familiar with the earlier versions of Ceph, you may be familiar with that process, as objects were not necessarily evenly distributed across the storage nodes of your cluster. Nowadays, and since somewhere around Firefly and Hammer, the default placement algorithm is way more effective on that matter.
Still, after a year running what started as a five hosts/three MONs/18 OSDs cluster, and grew up to eight hosts and 29 OSDs, two of them out – pending replacement – it finally happened, one of my disks usage went up to over 90%:
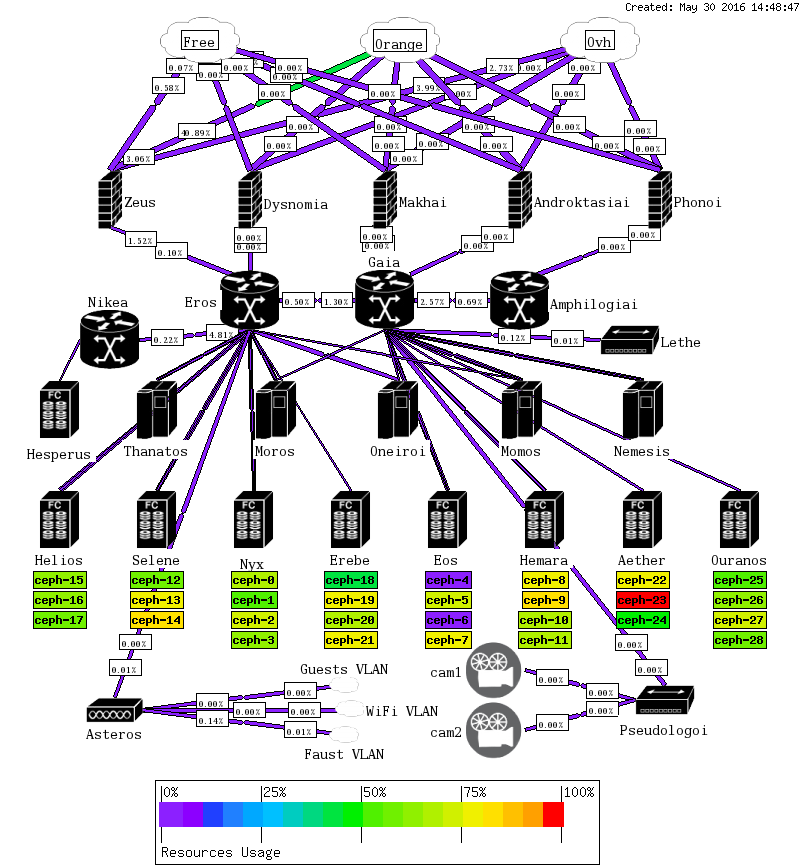
Ceph disks usage, before reweight
/dev/sdd1 442G 202G 241G 46% /var/lib/ceph/osd/ceph-24
/dev/sdb1 3.7T 2.7T 982G 74% /var/lib/ceph/osd/ceph-22
/dev/sdc1 1.9T 1.7T 174G 91% /var/lib/ceph/osd/ceph-23
/dev/sde1 3.7T 2.7T 1002G 74% /var/lib/ceph/osd/ceph-7
/dev/sdc1 3.7T 2.5T 1.2T 69% /var/lib/ceph/osd/ceph-5
/dev/sdb1 472G 67M 472G 1% /var/lib/ceph/osd/ceph-4
/dev/sdd1 3.7T 73M 3.7T 1% /var/lib/ceph/osd/ceph-6
/dev/sdc1 1.9T 1.2T 718G 62% /var/lib/ceph/osd/ceph-20
/dev/sdb1 2.8T 2.0T 778G 73% /var/lib/ceph/osd/ceph-19
/dev/sda1 442G 183G 260G 42% /var/lib/ceph/osd/ceph-18
/dev/sdd1 2.8T 2.0T 749G 74% /var/lib/ceph/osd/ceph-21
/dev/sdc1 927G 493G 434G 54% /var/lib/ceph/osd/ceph-17
/dev/sda1 1.9T 1.2T 717G 62% /var/lib/ceph/osd/ceph-15
/dev/sdb1 927G 519G 408G 56% /var/lib/ceph/osd/ceph-16
/dev/sda1 461G 324G 137G 71% /var/lib/ceph/osd/ceph-8
/dev/sdb1 3.7T 2.8T 953G 75% /var/lib/ceph/osd/ceph-9
/dev/sdc1 3.7T 2.2T 1.5T 61% /var/lib/ceph/osd/ceph-10
/dev/sdd1 2.8T 1.7T 1.1T 62% /var/lib/ceph/osd/ceph-11
/dev/sdd1 3.7T 2.1T 1.6T 57% /var/lib/ceph/osd/ceph-3
/dev/sdb1 3.7T 1.9T 1.9T 51% /var/lib/ceph/osd/ceph-1
/dev/sda1 472G 306G 166G 65% /var/lib/ceph/osd/ceph-0
/dev/sdc1 3.7T 2.5T 1.2T 68% /var/lib/ceph/osd/ceph-2
/dev/sda1 461G 219G 242G 48% /var/lib/ceph/osd/ceph-25
/dev/sdb1 2.8T 1.7T 1.1T 61% /var/lib/ceph/osd/ceph-26
/dev/sdc1 3.7T 2.5T 1.2T 68% /var/lib/ceph/osd/ceph-27
/dev/sdd1 2.8T 1.5T 1.3T 55% /var/lib/ceph/osd/ceph-28
/dev/sdc1 927G 696G 231G 76% /var/lib/ceph/osd/ceph-14
/dev/sda1 1.9T 1.1T 798G 58% /var/lib/ceph/osd/ceph-12
/dev/sdb1 2.8T 2.0T 804G 72% /var/lib/ceph/osd/ceph-13
It was time to do something:
ceph:~# ceph osd reweight-by-utilization
SUCCESSFUL reweight-by-utilization: average 0.653007, overload 0.783608. reweighted: osd.23 [1.000000 -> 0.720123]
about two hours later, all fixed:
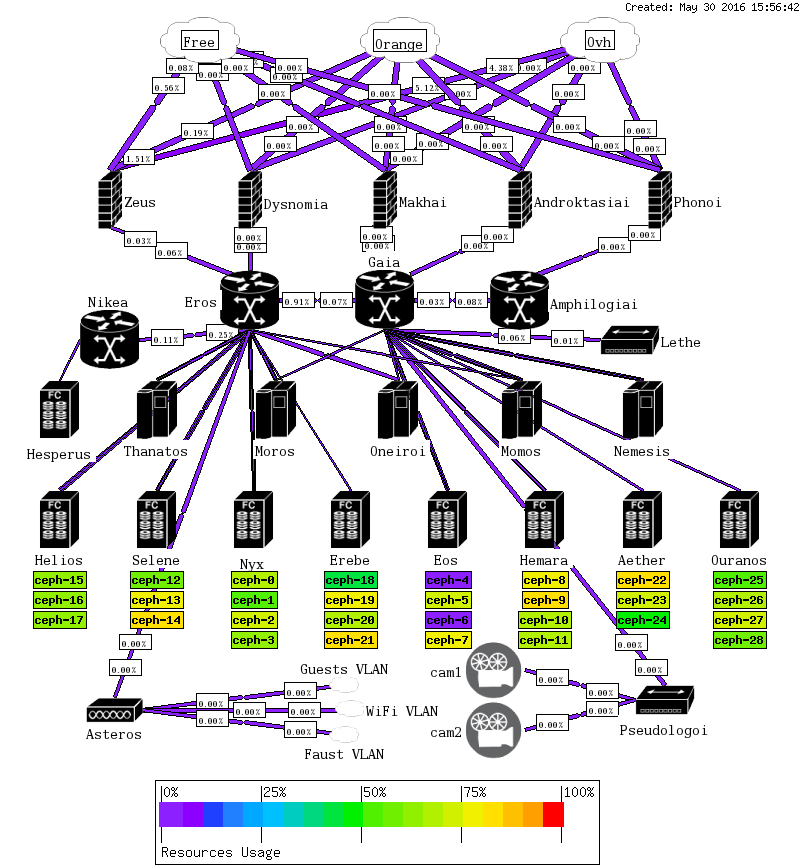
Ceph disks usage, after reweight
/dev/sdd1 442G 202G 241G 46% /var/lib/ceph/osd/ceph-24
/dev/sdb1 3.7T 2.8T 904G 76% /var/lib/ceph/osd/ceph-22
/dev/sdc1 1.9T 1.2T 638G 66% /var/lib/ceph/osd/ceph-23
/dev/sde1 3.7T 2.7T 976G 74% /var/lib/ceph/osd/ceph-7
/dev/sdc1 3.7T 2.5T 1.2T 69% /var/lib/ceph/osd/ceph-5
/dev/sdb1 472G 69M 472G 1% /var/lib/ceph/osd/ceph-4
/dev/sdd1 3.7T 75M 3.7T 1% /var/lib/ceph/osd/ceph-6
/dev/sdc1 1.9T 1.2T 666G 65% /var/lib/ceph/osd/ceph-20
/dev/sdb1 2.8T 2.0T 830G 71% /var/lib/ceph/osd/ceph-19
/dev/sda1 442G 183G 260G 42% /var/lib/ceph/osd/ceph-18
/dev/sdd1 2.8T 2.1T 696G 76% /var/lib/ceph/osd/ceph-21
/dev/sdc1 927G 518G 409G 56% /var/lib/ceph/osd/ceph-17
/dev/sda1 1.9T 1.2T 717G 62% /var/lib/ceph/osd/ceph-15
/dev/sdb1 927G 519G 408G 56% /var/lib/ceph/osd/ceph-16
/dev/sda1 461G 324G 137G 71% /var/lib/ceph/osd/ceph-8
/dev/sdb1 3.7T 2.8T 928G 76% /var/lib/ceph/osd/ceph-9
/dev/sdc1 3.7T 2.3T 1.4T 62% /var/lib/ceph/osd/ceph-10
/dev/sdd1 2.8T 1.7T 1.1T 62% /var/lib/ceph/osd/ceph-11
/dev/sdd1 3.7T 2.2T 1.5T 60% /var/lib/ceph/osd/ceph-3
/dev/sdb1 3.7T 1.9T 1.9T 51% /var/lib/ceph/osd/ceph-1
/dev/sda1 472G 306G 166G 65% /var/lib/ceph/osd/ceph-0
/dev/sdc1 3.7T 2.5T 1.2T 69% /var/lib/ceph/osd/ceph-2
/dev/sda1 461G 219G 242G 48% /var/lib/ceph/osd/ceph-25
/dev/sdb1 2.8T 1.7T 1.1T 62% /var/lib/ceph/osd/ceph-26
/dev/sdc1 3.7T 2.5T 1.2T 69% /var/lib/ceph/osd/ceph-27
/dev/sdd1 2.8T 1.6T 1.3T 56% /var/lib/ceph/osd/ceph-28
/dev/sdc1 927G 696G 231G 76% /var/lib/ceph/osd/ceph-14
/dev/sda1 1.9T 1.1T 798G 58% /var/lib/ceph/osd/ceph-12
/dev/sdb1 2.8T 2.0T 804G 72% /var/lib/ceph/osd/ceph-13
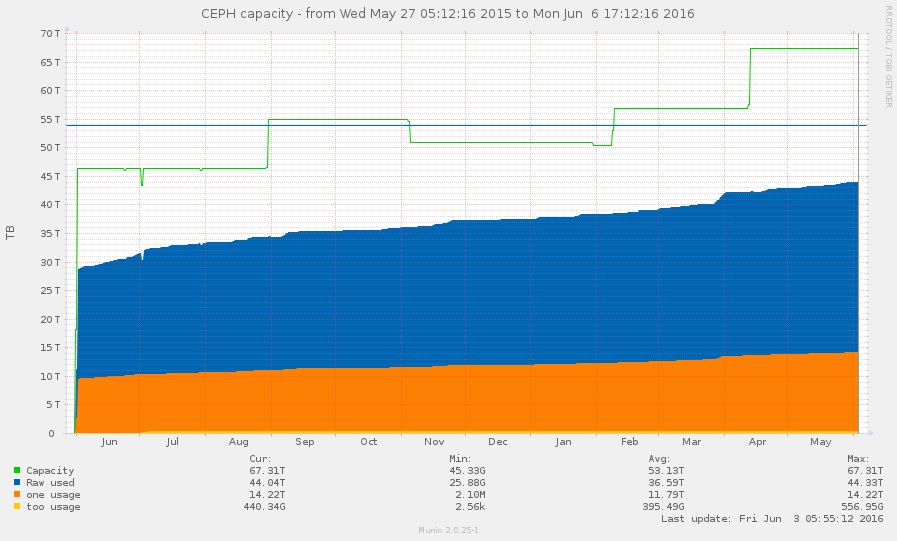
one year of ceph
I can’t speak for IO-intensive cases, although as far as I’ve seen the process of reweighting an OSD or repairing damaged placement groups blends pretty well with my usual workload.
Then again, Ceph provides with ways to priorize operations (such as backfill or recovery), allowing you to fine tune your cluster, using commands such as:
# ceph tell osd.* injectargs ‘–osd-max-backfills 1’
# ceph tell osd.* injectargs ‘–osd-max-recovery-threads 1’
# ceph tell osd.* injectargs ‘–osd-recovery-op-priority 1’
# ceph tell osd.* injectargs ‘–osd-client-op-priority 63’
# ceph tell osd.* injectargs ‘–osd-recovery-max-active 1’
While on the subject, last screenshot to celebrate one year running Ceph and OpenNebula, illustrating how much crap I can hoard.