OpenNebula

OpenNebula 4.10 dashboard, running on 4-compute 5-store cluster
This could have been the first article of this blog. OpenNebula is a modular cloud-oriented solution that could be compared to OpenStack, driving heterogeneous infrastructure, orchestrating storage, network and hypervisors configuration.
In the last 7 months, I’ve been using OpenNebula with Ceph to virtualize my main services, such as my mail server (200GB storage), my nntp index (200GB mysql DB, 300GB data), my wiki, plex, sabnzbd, … pretty much everything, except my DHCP, DNS, web cache and LDAP services.
A few before leaving Smile, I also used OpenNebula and Ceph to store our system logs, involving Elasticsearch, Kibana and rsyslog-om-elasticsearch (right: no logstash).
This week, some customer of mine was asking for a solution that would allow him to host several Cpanel VPS, knowing he already had a site dealing with customer accounts and billing. After refusing to use my scripts deploying Xen or KVM virtual machines, as well as some Proxmox-based setup, we ended up talking about OpenNebula.
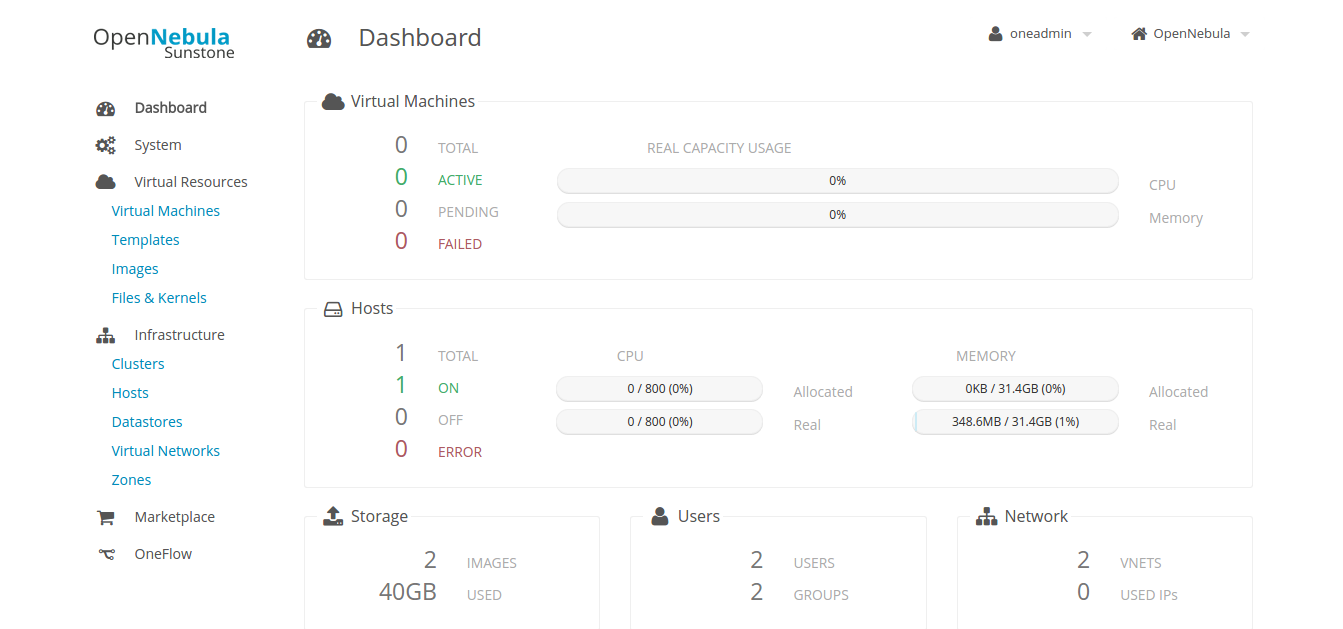
OpenNebula 4.12 dashboard, running on a single SoYouStart host
The service is based on a single SoYouStart dedicated host, 32GB RAM, 2x2T disks and a few public IPs.
Sadly, OpenNebula is still not available for Debian Jessie. Trying to install Wheezy packages, I met with some dependency issues, regarding libxmlrpc. In the end, I reinstalled the server with the latest Wheezy.
From there, installing Sunstone, OpenNebula host utils, registering localhost to my compute nodes and my LVM to my datastores took a couple hours.
Then, I started installing centos7 using virt-install and vnc, building cpanel, installing csf, adding my scripts configuring network according to nebula context media, … the cloud was operational five hours after Wheezy was installed.
I finished by writing some training support (15 pages, mostly screenshots) explaining the few actions required to create a VM for a new customer, suspend his account, backup his disks, and eventually purge his resources.
OpenNebula VNC view
At first glance, using OpenNebula to drive virtualization services on a single host could seem overkill, to say the least.
Though having a customer that don’t want to know what a shell looks like, and when even Proxmox is not an acceptable answer, I feel confident OpenNebula could be way more useful than we give it credit for.