Woozweb, Uptime Robot, StatusCake
Today, a post on a service that closed today, and investigating on potential replacements.

woozweb
In the last few years, I worked for Smile, a french Open Source integrator. Among other things, Smile hosted Woozweb, a free service allowing you to define HTTP checks, firing mail notifications.
Since I left Smile, I’ve opened an account on Woozweb, and used it looking after public services I manage, checking them from outside my facilities.
Two days ago, I received a mail from some Smile’s manager, notifying me that Woozweb would be shut down on May 13th. As of writing these lines (around 4 am), the site is indeed closed.
Such sites may seem stupid, or incomplete. And sure, the service those provide is really limited.
Yet when your monitoring setup is located in the same vLAN, or some network connected to the service you are monitoring, you should keep in mind your view on this service is not necessarily what your remote users would experience with. Hence, third-party services could stumble upon failures your own setup won’t even suspect.
Now Woozweb wasn’t perfect. Outdated web interface, outdated nagios probes (that failed establishing ssl handshake against my tlsv1.1/tlsv1.2 only services), 10 checks limitation, never got a response from their support, … But it did the job, allowed string matches, graphed response times, used to warn me when those reached a threshold, …
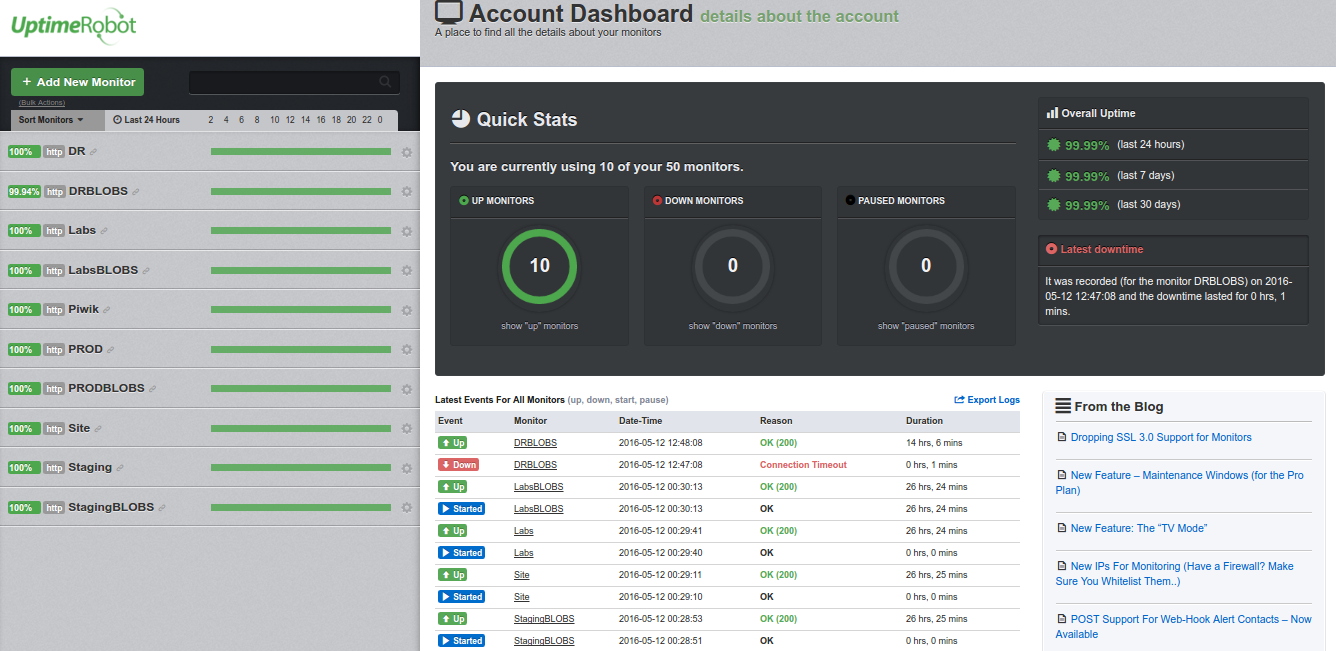
Uptime Robot dashboard
In the last couple days, I’ve been trying out alternatives to their service. There’s quite a lot of them, such as Pingdom. We’ll focus on free services, allowing https checks and triggering mail notifications.
The first I did test and could recommend is Uptime Robot.
Their interface is pretty nice and original. Service is free as long as you can stick to 50 checks with a 5 minutes interval, don’t need SMS notifications and can bear with 2 months of logs retention.
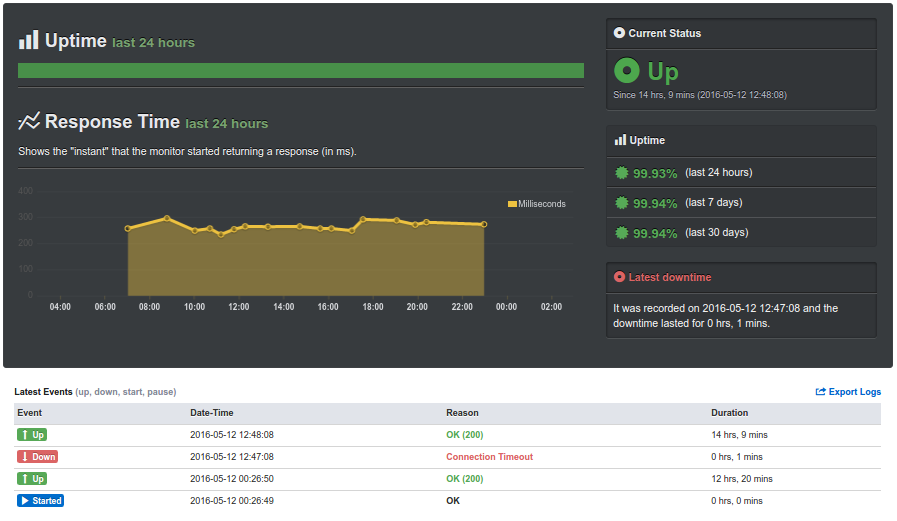
Uptime Robot check view
Defining checks is relatively easy, first results show up pretty quickly, no trouble checking tlsv1.1/tlsv1.2-only services. Already received an alert for a 1 minute outage, that my Icinga setup also warned me about.
Compared to Woozweb, the features are slightly better, whereas the web interface is definitely more pleasant. Yet there is no data regarding where those queries were issued from, and their paid plan page doesn’t mention geo-based checks – which is usually the kind of criteria we could look for, relying on such services.
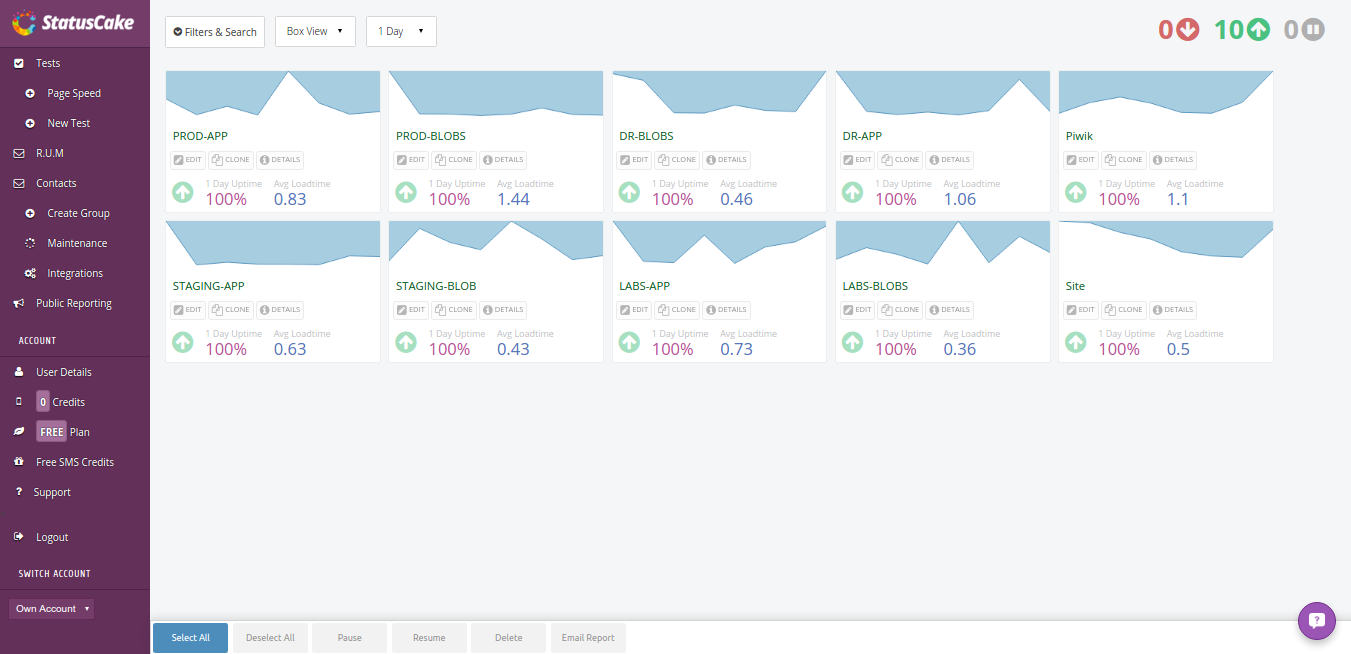
StatusCake dashboard
Not being completely satisfied, I looked for an other candidate and ended up trying out StatusCake.
Again, their site is pretty agreeable. Those used to CircleCI would recognize the navigation bar and support button. Free plan includes an unlimited amount of checks, as long as 5 minutes granularity is enough, and does involve running checks from random locations – whereas paid plans would allow you to pick from “60+” locations (according to their pricing page, while their site also tells about servers in over 30 countries and 100 locations around the world).
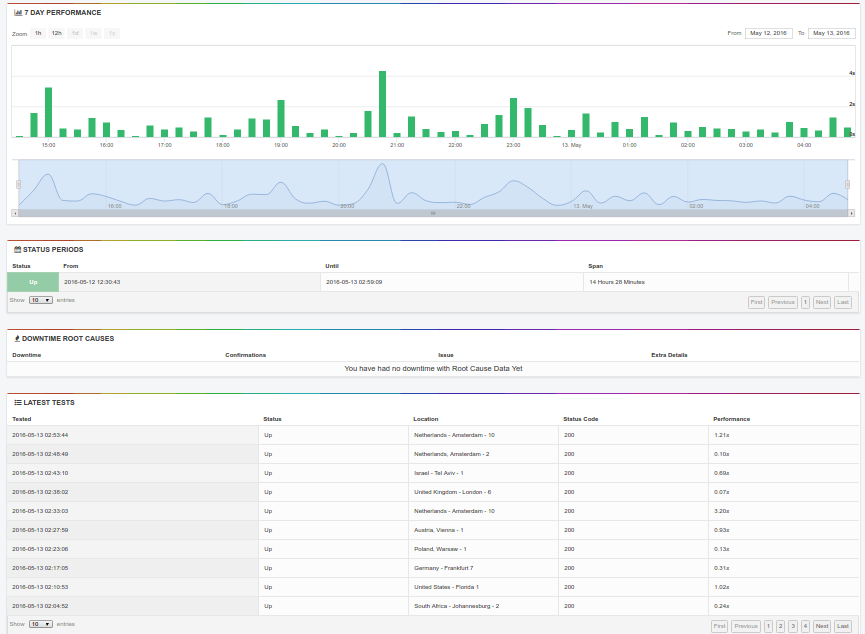
StatusCake check view
Defining checks is pretty easy. I liked the idea of being forced to define a contact group – which would allow you to change the list of recipient alerts should be send to, for several checks at once. Yet the feature that definitely convinced me with Slack integration.
So even if you do not want to pay for a plan including SMS notifications, you could receive notifications on your phone using Slack.
Everything’s not perfect though: string matches are only allowed using paid plans. This kind of feature is pretty basic, … On the bright side, status-code based filtering is nicely done.
The check view confirms your service is monitored from various locations. It is maybe a little less appealing than Uptime Robot, but the Slack integration beats everything.
Another big advantage StatusCake has is their “Public Reporting” capabilities. I’m not sure I would use it right now, as I already wrote a small shell-script based website, serving as public reporting dashboard, that I host outside of our production setup.
Bearing in mind these service won’t exempt you from setting up some in-depth and exhaustive monitoring of your resources, they still are a nice addition. Sexy dashboards definitely help – I wouldn’t have shown Woozweb screenshots, as their UI was amazingly despicable.
I’ll probably keep using both Uptime Robot and StatusCake.