Mesos
Today we would take a short break from Kubernetes, and try out another container orchestration solution: Mesos.
Mesos is based on a research project, first presented in 2009 under the name of Nexus. Its version 1 was announced in 2016 by the Apache Software Foundation. In April 2021, a vote concluded Mesos should be moved to the Apache Attic, suggesting it reached end of life, though that vote was later cancelled, due to increased interest.
A Mesos cluster is based on at least three components: a Zookeeper server (or cluster), a set of Mesos Master and the Mesos Slave agent, that would run on all nodes in our cluster. Which could be compared to Kubernetes etcd, control plane and kubelet respectively.
Setting it up, we would install Mesos Repository (on CentOS7: http://repos.mesosphere.io/el/7/noarch/RPMS/mesosphere-el-repo-7-1.noarch.rpm), then install the mesos package on all nodes, as well as mesosphere-zookeeper on the Zookeeper nodes.
Make sure /etc/mesos/zk points to your Zookeeper node(s).
Open ports 2181/tcp on your Zookeeper nodes, port 5050/tcp on master nodes, and 5051/tcp on agents.
Start zookeeper, mesos-master and mesos-slave services.
We should be able to connect our Master console, on port 5050, and confirm our agents have properly registered.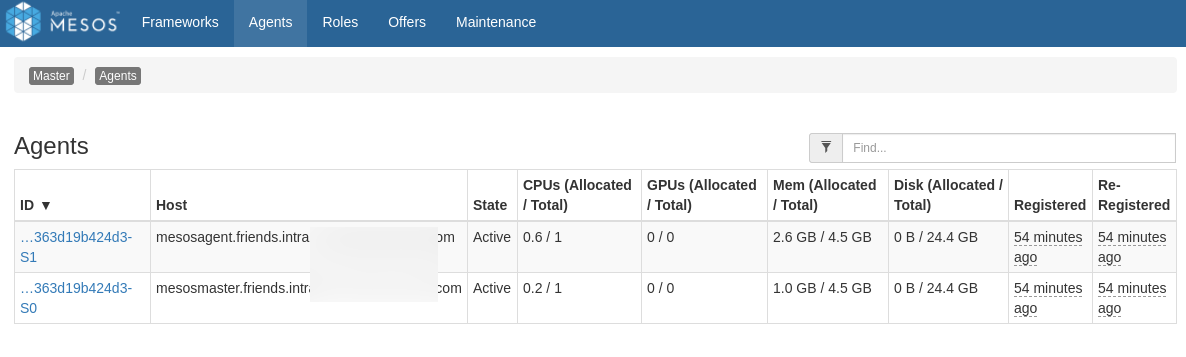
With Mesos, we are likely to first deploy some frameworks, that would then orchestrate our applications deployment.
Frameworks would take care of scheduling workloads on your behalf, using Mesos resources. The first one we should look into is Marathon, which could be compared to Kubernetes Deployment and StatefulSets controller, in that it would ensure an application is “always on”.
We may deploy Marathon on a separate node, or to an existing Mesos instance, installing the marathon package from the same repository we installed Mesos from. Note that CentOS7 default JRE seems to be an issue running Marathon latest releases: you may want to install marathon-1.4 instead.
Marathon listens on port 8080/tcp, which should be opened as well. Having done so, we may connect the Marathon UI to deploy our applications – or POST json objects to its API.
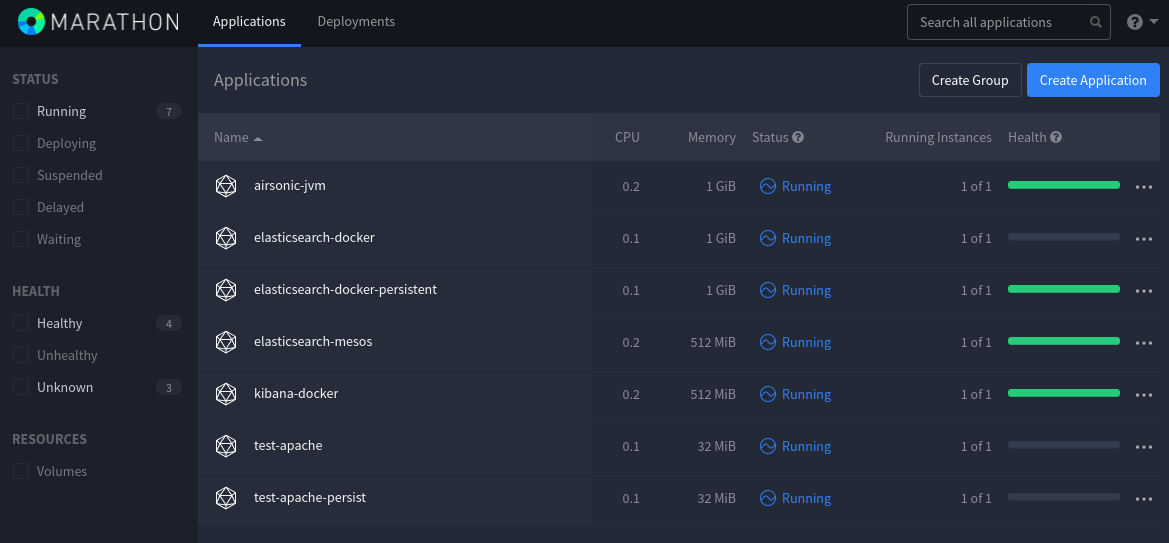
Now, we could look into what makes Mesos interesting, when compared with Kubernetes.
You may know Mesos can be used deploying Docker container, which would be done posting something like the following, to the Marathon API:
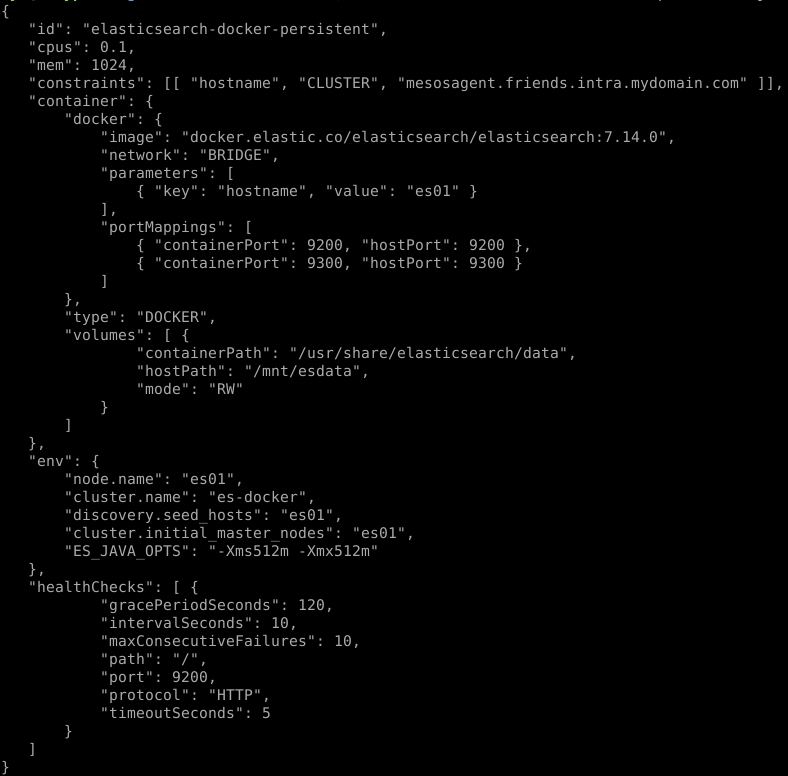
Though the above relies on the Docker runtime, which is not mandatory, using Mesos.
Indeed, we could describe the same deployment, with the following:
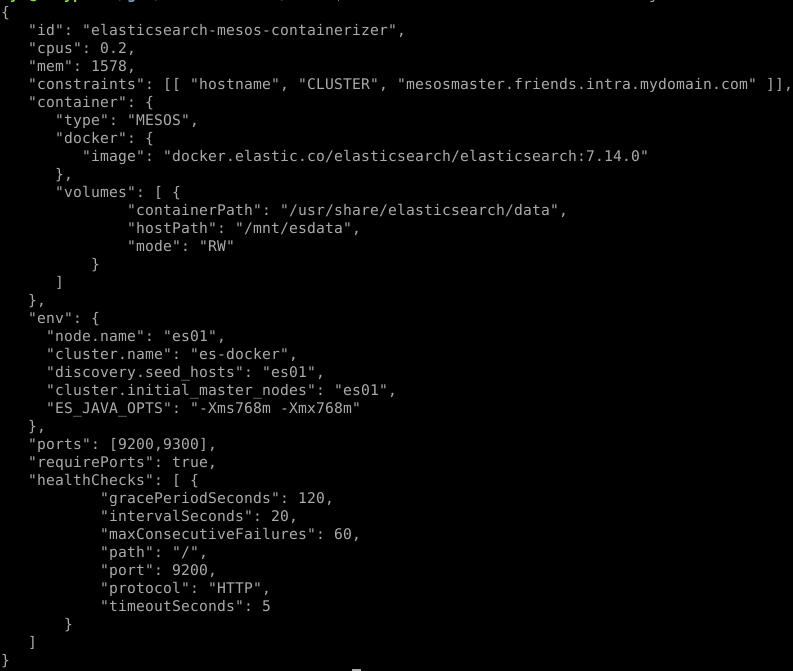
Mesos comes with its own containerizer, able to start applications from OCI images.
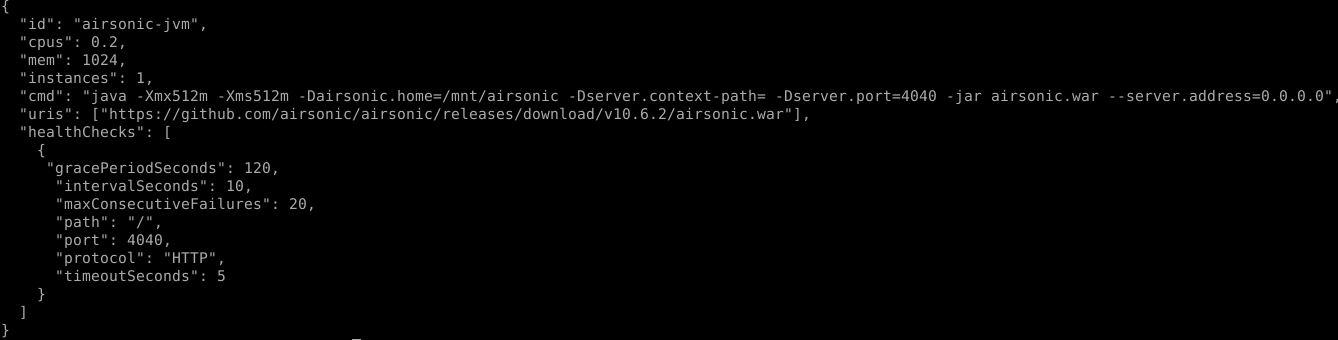
We could also note that Mesos may be used managing services, based on binary or whatever asset we may pull out of an HTTP repository – or already present, on our nodes filesystem. To demonstrate this, we could start some Airsonic application, posting the following to Marathon:
Going further, we should look into other frameworks, such as Chronos – somewhat comparable to Kubernetes Jobs controller.
PID / IPC / network / filesystem / … isolations may be implemented using isolators. Though a lot of features we would usually find in Kubernetes would here be optional.
Nevertheless, deployments are pretty fast considering the few resources I could allocate that lab. With the vast majority of container orchestration solutions being based on the same projects nowadays, it’s nice to see a contestant with its own original take. Even though Mesos probably suffers from limited interest and contributions, when compared with Kubernetes.