OpenShift
As of late 2017, I got introduced to OpenShift. Even though I’ve only been playing with a few basic features, nesting Docker into static KVMs, I was pretty impressed by the simplicity of services deployment, as served to end-users.

After replacing 4x MicroServer, by 3x SE318m1
I’ve first tried setting my own, re-using my ProLian MicroServers. One of my master node was refusing to deploy, CPU usage averaging around 100%, systemctl consistently timing out while starting some process – that did start on my two other master nodes.
After trying to resize my KVMs in vain, I eventually went another way: shut down a stair of ProLian MicroServer, move them out of my rack and plug instead 3 servers I ordered a couple years ago, that never reached prod – due to doubts regarding overall power consumption, EDF being able to deliver enough Amperes, my switches not being able to provide with enough LACP channels, my not having enough SSDs or quad-port Ethernet cards in stock to fill these servers, …
I eventually compromised, and harvested any 500G SSDs disks available out of my Ceph cluster, mounting one per 1U server.
Final setup involves the following physical servers:
- a custom tower (core i5, 32G DDR, 128G SSD disk)
-
3x HP SE316M1 (2xE5520, 24G DDR) – 500G SSD
-
2x HP SE1102 (2xE5420 12G DDR) – 500G SSD
-
3x ProLian MicroServer G5 (Turion, 4-8G DDR) – 64G SSD + 3×3-4T HDD
And on top of these, a set of KVM instances, including:
- 3 master nodes (2 CPU, 8G RAM)
- 3 infra nodes (2 CPU, 6G RAM)
- 3 compute nodes (4 CPU, 10G RAM @SE316M1)
- 3 storage nodes (1 CPU, 3G RAM @MicroServer)
Everything running on CentOS7. Except for some Ansible DomU I would use deploying OpenShift, running Debian Stretch.
OpenShift can be deployed using Ansible. And as I’ve been writing my own roles for the past couple years, I can testify these ones are amazing.
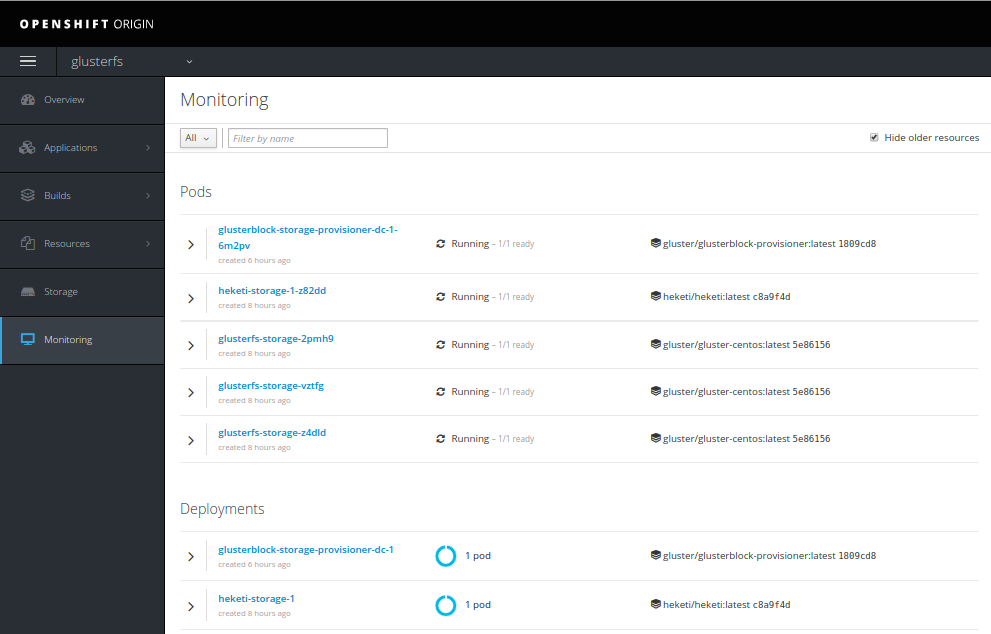
GlusterFS @OpenShift
First ansible run would be done setting the following variables, bootstrapping service on top of my existing domain name, and LDAP server.
ansible_ssh_user: root
openshift_deployment_type: origin
openshift_disable_check: disk_availability,docker_storage,memory_availability
openshift_master_cluster_method: native
openshift_master_cluster_hostname: openshift.intra.unetresgrossebite.com
openshift_master_cluster_public_hostname: openshift.intra.unetresgrossebite.com
openshift_master_default_subdomain: router.intra.unetresgrossebite.com
openshift.common.dns_domain: openshift.intra.unetresgrossebite.com
openshift_clock_enabled: True
openshift_node_kubelet_args: {‘pods-per-core’: [’10’], ‘max-pods’: [‘250’], ‘image-gc-high-threshold’: [’90’], ‘image-gc-low-threshold’: [’80’]}
openshift_master_identity_providers:
– name: UneTresGrosseBite
challenge: ‘true’
login: ‘true’
kind: LDAPPasswordIdentityProvider
attributes:
id: [‘dn’]
email: [‘mail’]
name: [‘sn’]
preferredUsername: [‘uid’]
bindDN: cn=openshift,ou=services,dc=unetresgrossebite,dc=com
bindPassword: secret
ca: ldap-chain.crt
insecure: ‘false’
url: ‘ldaps://netserv.vms.intra.unetresgrossebite.com/ou=users,dc=unetresgrossebite,dc=com?uid?sub?(&(objectClass=inetOrgPerson)(!(pwdAccountLockedTime=*)))’
openshift_master_ldap_ca_file: /root/ldap-chain.crt
Setting up glusterfs, note you may have difficulties setting gluster block devices as group vars, and could find a solution sticking to defining these directly into your inventory file:
[glusterfs]
gluster1.friends.intra.unetresgrossebite.com glusterfs_ip=10.42.253.100 glusterfs_devices='[ “/dev/vdb”, “/dev/vdc”, “/dev/vdd” ]’
gluster2.friends.intra.unetresgrossebite.com glusterfs_ip=10.42.253.101 glusterfs_devices='[ “/dev/vdb”, “/dev/vdc”, “/dev/vdd” ]’
gluster3.friends.intra.unetresgrossebite.com glusterfs_ip=10.42.253.102 glusterfs_devices='[ “/dev/vdb”, “/dev/vdc”, “/dev/vdd” ]’
Apply the main playbook with:
ansible-playbook playbooks/byo/config.yml -i ./hosts
Have a break: with 4 CPUs & 8G RAM on my ansible host, applying a single variable change (pretty much everything was installed beforehand), I would still need over an hour and a half applying the full playbook: whenever possible, stick to whatever service-specific playbook you may find, …
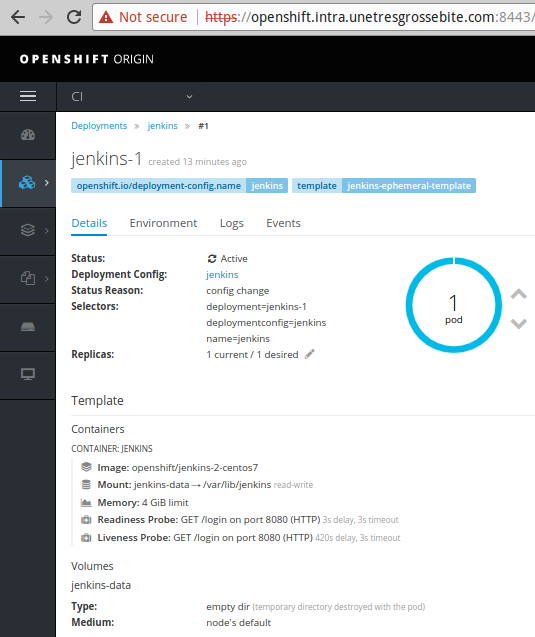
Jenkins @OpenShift
As a sidenote, be careful to properly set your domain name before deploying glusterfs. So far, while I was able to update my domain name almost everywhere running Ansible playbooks back, GlusterFS’s hekiti route was the first I noticed not being renamed.
Should you fuck up your setup, you can use oc project glusterfs then oc get pods to locate your running containers, use oc rsh <container> then rm -fr /var/lib/hekiti to purge stuff that may prevent further deployments, …
Then oc delete project glusterfs, to purge almost everything else.
You may also use running docker images | grep gluster and docker rmi <images>, … As well as making sure to wipe the first sectors of your gluster disks (for d in b c d; do dd if=/dev/zero of=/dev/vd$d bs=1M count=8; done). You may need to reboot your hosts (if a wipefs -a /dev/drive returns with an error). Finally, re-deploy a new GlusterFS cluster from scratch using Ansible.
Once done with the main playbook, you should be able to log into your OpenShift dashboard. Test it by deploying Jenkins.
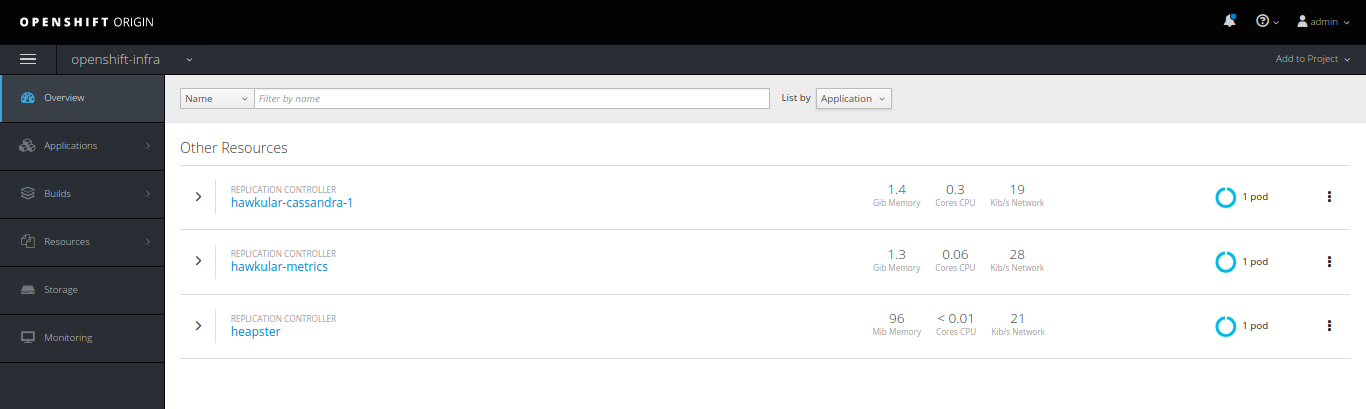
Hawkular integration @OpenShift
You could (should) also look into deploying OpenShift cluster metrics collection, based on Hawkular & Heapster.
Sticking with volatile storage, you would need adding the following variable to all your hosts:
openshift_metrics_install_metrics: True
Note to deploy these roles, you would have to install on your Ansible host (manually!) python-passlib, apache2-utils and openjdk-8-jdk-headless (assuming Debian/Ubuntu). You may then deploy metrics using the playbooks/byo/openshift-cluster/openshift-metrics.yml playbook.
Hawkular integration would allow you to track resources usage directly from OpenShift dashboard.

Prometheus @OpenShift
You could also setup Prometheus defining the following:
openshift_prometheus_namespace: openshift-metrics
openshift_prometheus_node_selector: {“region”:”infra”}
And applying the playbooks/byo/openshift-cluster/openshift-prometheus.yml playbook.
You should also be able to setup some kind of centralized logging based on ElasticSearch, Kibana & Fluentd, using the following:
openshift_logging_install_logging: True
openshift_logging_kibana_hostname: kibana.router.intra.unetresgrossebite.com
openshift_logging_es_memory_limit: 4Gi
openshift_logging_storage_kind: dynamic
openshift_cloudprovider_kind: glusterfs
Although so far, I wasn’t able to get it running properly ElasticSearch health is stuck to yellow, while Kibana and Fluentd can’t reach it somehow, could be due to a missing DNS record.
From there, you would find plenty solutions, packaged for OpenShift, ready to deploy (a popular one seems to be Go Git Server).
Deploying new services can still be a little painful, although there’s no denying OpenShift offers with a potentially amazing SAAS toolbox.