Kibana
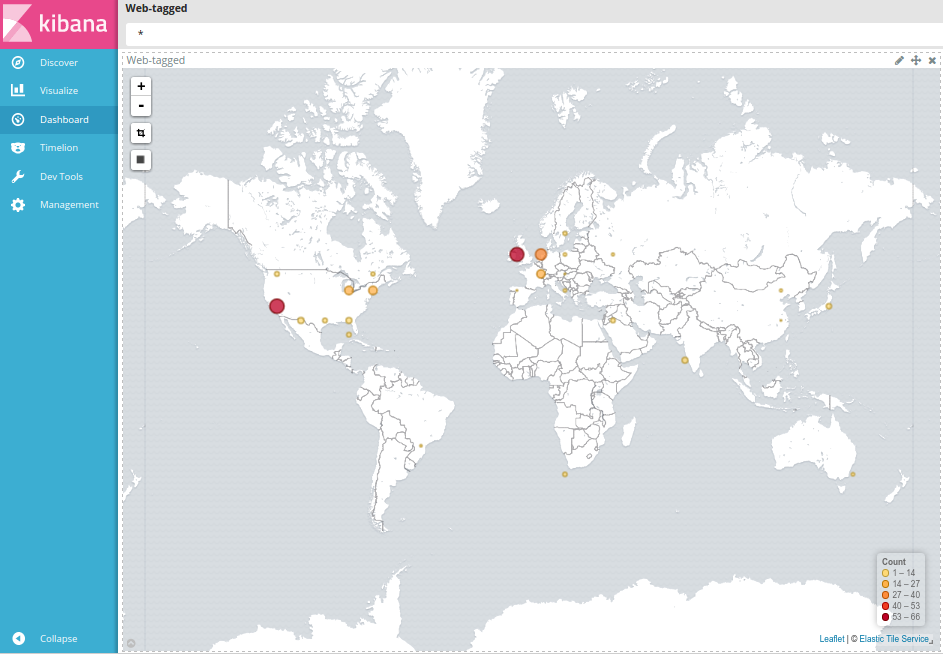
Kibana Map
Kibana is the visible part of a much larger stack, based on ElasticSearch, a distributed search engine based on Lucene, providing with full-text searches via some restful HTTP web service.
Kibana used to be a JavaScript application running from your browser, querying some ElasticSearch cluster and rendering graphs, maps, … listing, counting, … A couple versions ago, kibana was rewritten as a NodeJS service. Nowadays, Kibana can even be used behind a proxy, allowing you to configure some authentication, make your service public, …
ElasticSearch on the other hand, is based on Java. Latest versions would only work with Java 8. We won’t make an exhaustive changes list, as this is not our topic, although we could mention that ElasticSearch 5 no longer uses their multicast discovery protocol, and instead defaults to unicast. You may find plugins such as X-Pack, that would let you plug your cluster authentication to some LDAP or AD backend, configuring Role-Based Access Control, … the kind of stuff that used to require a Gold plan with Elastic.co. And much more …
One of the most popular setup involving Kibana also includes Logstash, which arguably isn’t really necessary. An alternative to “ELK” (ElasticSearch Logstash Kibana) could be to replace your Logstash by Rsyslog, leveraging its ElasticSearch output module (om-elasticsearch). Then again, Logstash can be relevant assuming you need to apply transformations to your logs (obfuscating passwords, generating geo -locations data from an IP address, …). Among other changes, Logstash 5 requires GeoIP databases to comply with the new MaxMind DB binary format.
Kibana Filters
All of these projects are evolving quickly – even syslog, whose 8th version doesn’t look anything like the version 5, that used to be on the previous debian LTS.
Having reinstalled a brand new cluster to celebrate, I had to rewrite my puppet modules deploying ElasticSearch and Kibana, pretty much everything changed, variables renamed, new repositories, introducing Kibana debian packages, …
Kibana as well, was subject to major changes: panels are no longer loaded from Kibana yaml configuration file: something very similar to the previous default dashboard is loaded and you may install additional plugins, as you may already do customizing Logstash or ElasticSearch. Meanwhile, Kibana is finally shipped as a debian archive, corresponding init scripts are properly installed, … Way cleaner, rewriting this puppet module was a pleasure.

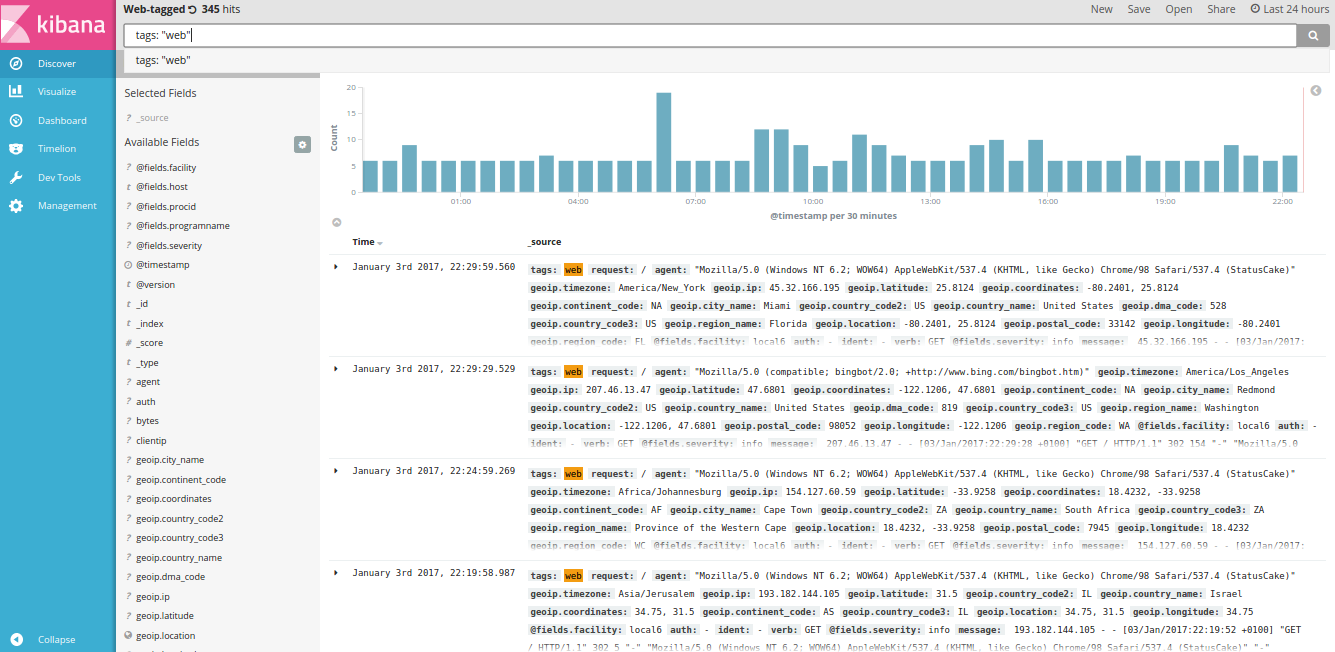
Kibana Discovery
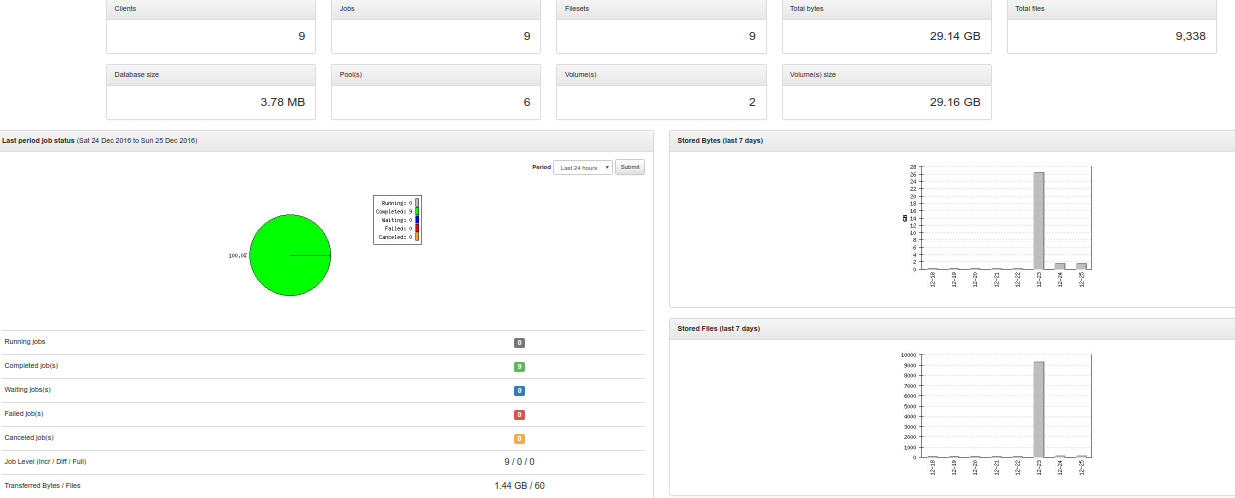
Note that the test setup I am currently running is hosted on a tiny Kimsufi box, 4G RAM, Atom 2800 CPU, 40G disk. This server runs ElasticSearch, Kibana, Logstash – and Rsyslog. Such RAM or CPU is kinda small, for ELK. Still, I must say I’m pretty satisfied so far. Kibana dashboard loads in a couple seconds, which is way faster than my recollections running single-node ELKs with previous versions, and definitely faster than running a 3-nodes ELK-4 cluster for a customer of mine.