OpenShift Egress Traffic Management
Today, I’m investigating yet another OpenShift feature: Egress Routers. We would look at how to ensure a given connection leaves our cluster using a given IP address, integrating OpenShift with existing services that would be protected by some kind of IP filter.
First, let’s explain the default behavior of OpenShift.
Deployments are scheduled on OpenShift hosts, eventually leading to containers being started on those nodes.
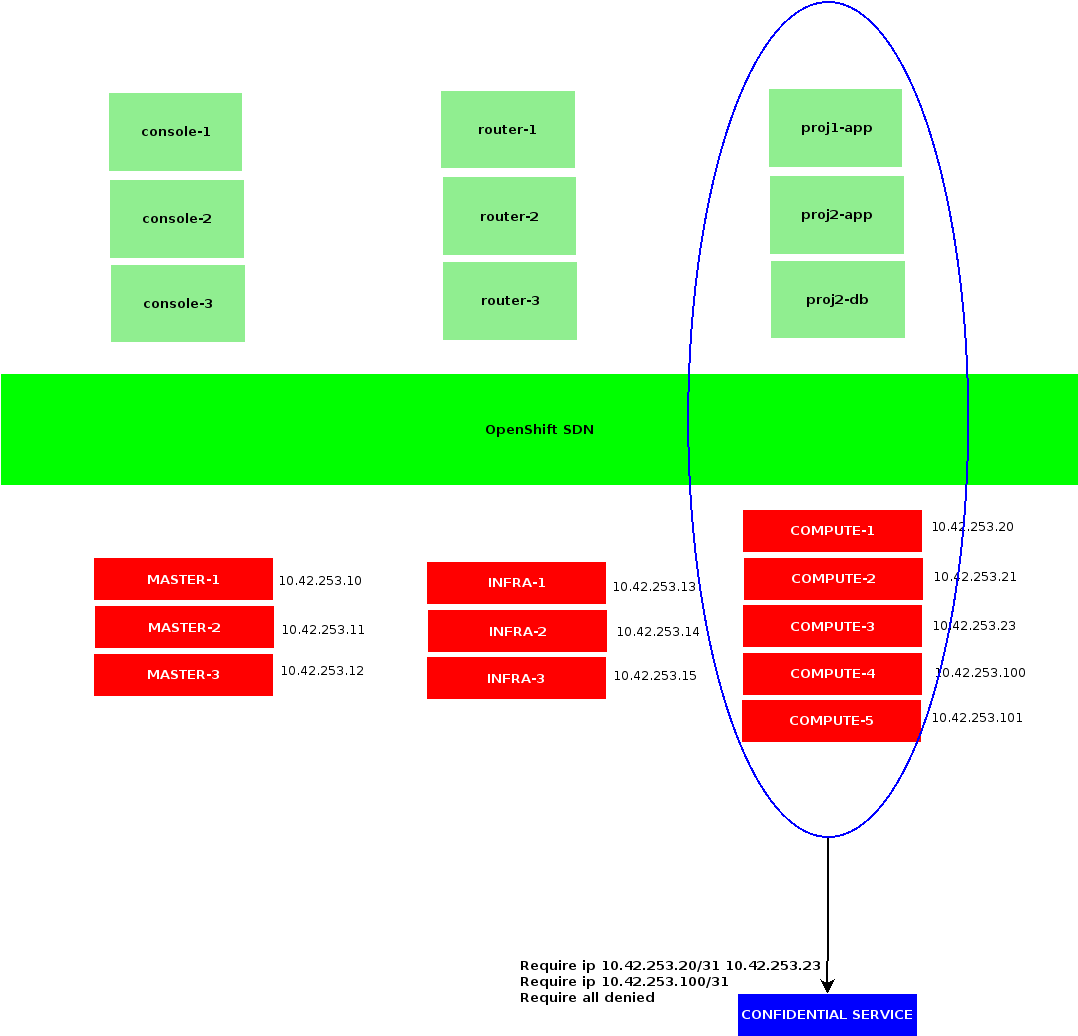
Filtering OpenShift compute hosts IPs
Whenever contacting a service outside OpenShift SDN, a container would exit OpenShift network through the node it’s been started on. Meaning the corresponding connection would get NAT-ed using the node IP our container currently is.
As such, a straight forward way of allowing OpenShift containers to reach a protected service could be to trust all my OpenShift hosts IP addresses connecting to those services.
Note that this sample implies trusting all containers that may be scheduled on those OpenShift nodes, contacting our remote service. It could be acceptable in a few cases, although whenever OpenShift is shared among multiple users or tenants, it usually won’t.
While we could address this by dedicating OpenShift nodes to users requiring access to a same set of protected resources, we would remain limited by the amount of OpenShift nodes composing our cluster.
Instead of relying on OpenShift nodes addresses, we could involve additional addresses dedicated to accessing external resources.
A first way to implement this would be to allocate an OpenShift namespace with its own Egress IPs:
$ oc patch netnamespace toto -p ‘{“egressIPs”: [“10.42.253.45″,”10.42.253.54”]}’
Such configuration would also require us to associate these egress IPs to OpenShift nodes’ hostsubnet:
$ oc patch hostsubnet compute3 -p ‘{“egressIPs”: [“10.42.253.45”]}’
$ oc patch hostsubnet compute1 -p ‘{“egressIPs”: [“10.42.253.54”]}’
Then, from a Pod of our toto netnamespace, we could try to reach a remote service:
$ oc rsh -n toto jenkins-1-xyz
sh-4.2$ ping 8.8.8.8
[…]
64 bytes from 8.8.8.8: icmp_seq=90 ttl=119 time=4.01 ms
64 bytes from 8.8.8.8: icmp_seq=91 ttl=119 time=4.52 ms
^C
— 8.8.8.8 ping statistics —
91 packets transmitted, 89 received, 2% packet loss, time 90123ms
rtt min/avg/max/mdev = 3.224/4.350/12.042/1.073 ms
Notice we did lost a few packets. The reason for this is that I rebooted the compute3 host, from which my ping was initially leaving the cluster. While the node was marked NotReady, traffic went through the second node, compute1, holding an egressIP associated to the toto netnamespace. From our gateway, we can confirm the new IP is temporarily being used:
# tcpdump -vvni vlan5 host 10.42.253.54
tcpdump: listening on vlan5, link-type EN10MB
13:11:13.066821 10.42.253.54 > 8.8.8.8: icmp: echo request (id:023e seq:3) [icmp cksum ok] (DF) (ttl 63, id 24619, len 84)
13:11:13.070596 arp who-has 10.42.253.54 tell 10.42.253.5
13:11:13.071194 arp reply 10.42.253.54 is-at 52:54:00:b1:15:b9
13:11:13.071225 8.8.8.8 > 10.42.253.54: icmp: echo reply (id:023e seq:3) [icmp cksum ok] [tos 0x4] (ttl 120, id 14757, len 84)
13:11:14.066796 10.42.253.54 > 8.8.8.8: icmp: echo request (id:023e seq:4) [icmp cksum ok] (DF) (ttl 63, id 25114, len 84)
13:11:14.069990 8.8.8.8 > 10.42.253.54: icmp: echo reply (id:023e seq:4) [icmp cksum ok] [tos 0x4] (ttl 120, id 515, len 84)
As soon as compute3 is done rebooting, tcpdump confirms 10.42.253.54 is no longer used.
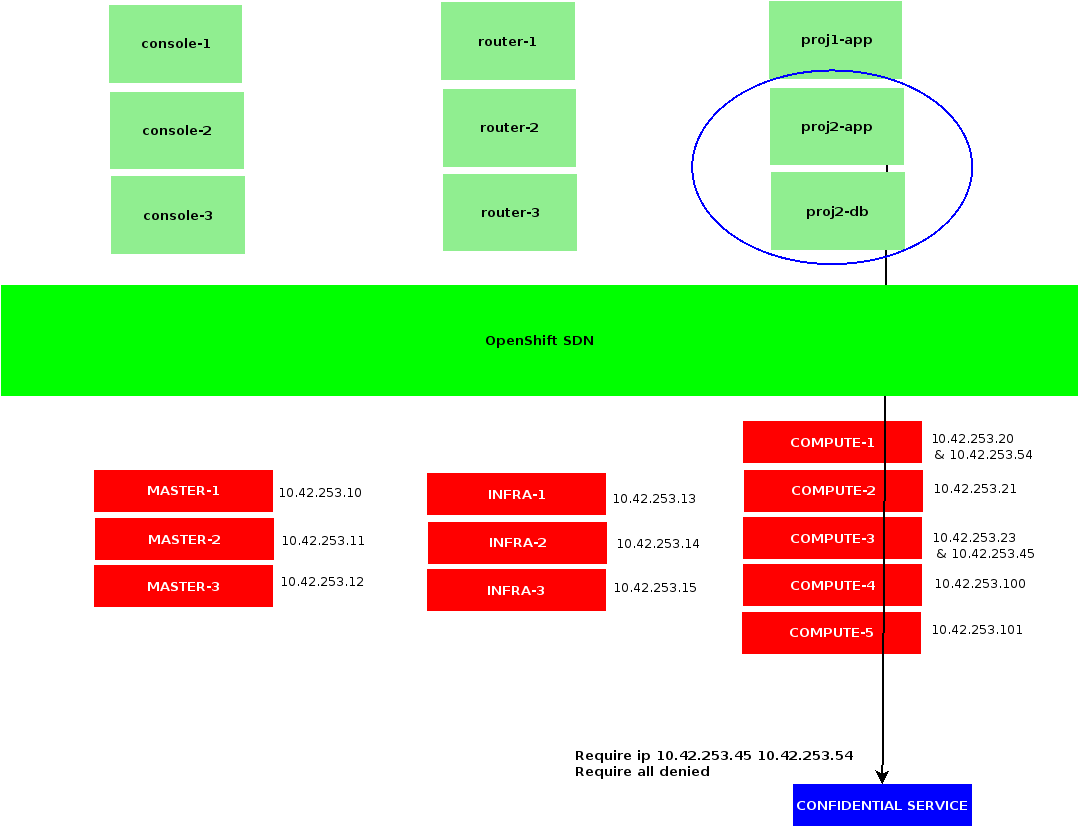
Namespace-based IP Filtering
From the router point of view, we can see that the hardware address for our Egress IPs match those of our OpenShift hosts:
# arp -na | grep 10.42.253
[…]
10.42.253.20 52:54:00:b1:15:b9 vlan5 19m49s
10.42.253.21 52:54:00:6b:99:ad vlan5 19m49s
10.42.253.23 52:54:00:23:1c:4f vlan5 19m54s
10.42.253.45 52:54:00:23:1c:4f vlan5 7m36s
10.42.253.54 52:54:00:b1:15:b9 vlan5 10m35s
As such, this configuration may be preferable whenever the network hosting OpenShift would not allow introducing virtual hardware addresses.
Note that usage for a node’s EgressIP is reserved to the netnamespaces specifically requesting them. Any other container executed on my compute1 and compute3 hosts are still being NAT-ed using 10.42.253.20 and 10.42.253.23 respectively.
Also note that namespace based IP filtering does not rely on any placement rule: containers could get started on any OpenShift node in your cluster, their traffic would still exit OpenShift SDN through a designated node, according to netnamespaces and hostsubnets configurations.
Bearing in mind that whenever the EgressIPs from your netnamespaces are no longer assigned to a node from your cluster – be that due to a missing configuration, or an outage affecting all your Egress hosts – then containers from the corresponding projects would no longer have access to resources out of OpenShift SDN.
Now that we’re familiar with the basics of OpenShift Egress traffic management, we can focus on Egress Routers.
Several Egress Routers implementation exist, we would focus on the couple most commons that are the Redirect mode, and the HTTP proxy mode.
In both cases, we would use a dedicated project hosting a router Pod:
$ oc new-project egress-routers
We would also rely on a ServiceAccount, that may start privileged containers:
$ oc create sa egress-init
As well as a SecurityContextContraint granting our ServiceAccount such privileges:
$ cat <<EOF >egress-scc.yml
kind: SecurityContextConstraints
apiVersion: v1
metadata: { name: egress-init }
allowPrivilegedContainer: true
runAsUser: { type: RunAsAny }
seLinuxContext: { type: RunAsAny }
fsGroup: { type: RunAsAny }
supplementalGroups: { type: RunAsAny }
users: [ “system:serviceaccount:egress-routers:egress-init” ]
EOF
$ oc create -f egress-scc.yml
Running a Redirect Egress Router, we would then create a controller ensuring a Pod would deal with configuring OpenShift SDN NAT-ing the traffic with a specific Egress IP:
$ cat <<EOF >redirect-router.yml
apiVersion: v1
kind: ReplicationController
metadata:
name: egress-router
spec:
replicas: 1
selector:
name: egress-router
template:
metadata:
name: egress-router
labels:
name: egress-router
annotations:
pod.network.openshift.io/assign-macvlan: “true”
spec:
initContainers:
– name: egress-demo-init
image: docker.io/openshift/origin-egress-router
env:
– name: EGRESS_SOURCE
value: 10.42.253.46
– name: EGRESS_GATEWAY
value: 10.42.253.1
– name: EGRESS_DESTINATION
value: 8.8.8.8
– name: EGRESS_ROUTER_MODE
value: init
securityContext:
privileged: true
serviceAccountName: egress-init
containers:
– name: egress-demo-wait
image: docker.io/openshift/origin-pod
nodeSelector:
node-role.kubernetes.io/infra: “true”
serviceAccountName: egress-init
EOF
$ oc create -f redirect-router.yml
Note we are first starting an init container setting up proper iptalbes rules using a few variables. EGRESS_SOURCE is an arbitrary and un-allocated IP address in OpenShift subnet, EGRESS_GATEWAY is our default gateway and EGRESS_DESTINATION the remote address our Egress router would forward its traffic to.
Once our init container is done updating iptables configuration, it is shut down and replaced by our main pod, that would not do anything.
At that point, we could enter that Pod, and see that all its traffic exit OpenShift subnet being NAT-ed with our EGRESS_SOURCE IP, by the OpenShift host executing our container.
From the network gateway point of view, we could notice our EGRESS_SOURCE_IP address is associated to a virtual hardware address:
# arp -na | grep 10.42.253
[…]
10.42.253.46 d6:76:cc:f4:e3:d9 vlan5 19m34s
Contrarily to namespace-scoped Egress IPs, Egress Routers may be scheduled anywhere on OpenShift cluster, according to an arbitrary – and optional – placement rule. Although it relies on containers, which might take a few seconds to start depending on images being available in Docker local caches. Another drawback being that a single IP can not be shared among several routers, we would not be able to scale them.
To offer with redundancy, we could however setup several Egress Routers per protected service, using distinct EGRESS_SOURCE, and sharing the same EGRESS_DESTINATION.
While we’ve seen our Egress Router container exits our cluster to any remotes using our designated EGRESS_SOURCE address, let’s now look at how to use that router from other OpenShift hosted containers. First, we would create a service identifying our Egress Routers:
$ oc create service –name egress-redirect –namespace egress-routers –port=53 –selector=name=egress-router
Depending on your network plugin we would have to allow traffic coming to that service from third-party Projects. We would then be able to query our EGRESS_DESTINATION through our service:
$ curl http://egress-redirect.egress-routers.svc:53/
From our gateway, we could see the corresponding traffic leaving OpenShift SDN, NAT-ed using our EGRESS_SOURCE:
# tcpdump -vvni vlan5 host 8.8.8.8
tcpdump: listening on vlan5, link-type EN10MB
11:11:53.357775 10.42.253.46.53084 > 8.8.8.8.53: S [tcp sum ok] 1167661839:1167661839(0) win 28200 <mss 1410,sackOK,timestamp 84645569 0,nop,wscale 7> (DF)
11:11:54.357948 10.42.253.46.53084 > 8.8.8.8.53: S [tcp sum ok] 1167661839:1167661839(0) win 28200 <mss 1410,sackOK,timestamp 84646572 0,nop,wscale 7> (DF)
11:11:56.361964 10.42.253.46.53084 > 8.8.8.8.53: S [tcp sum ok] 1167661839:1167661839(0) win 28200 <mss 1410,sackOK,timestamp 84648576 0,nop,wscale 7> (DF)Redirect Egress Routers
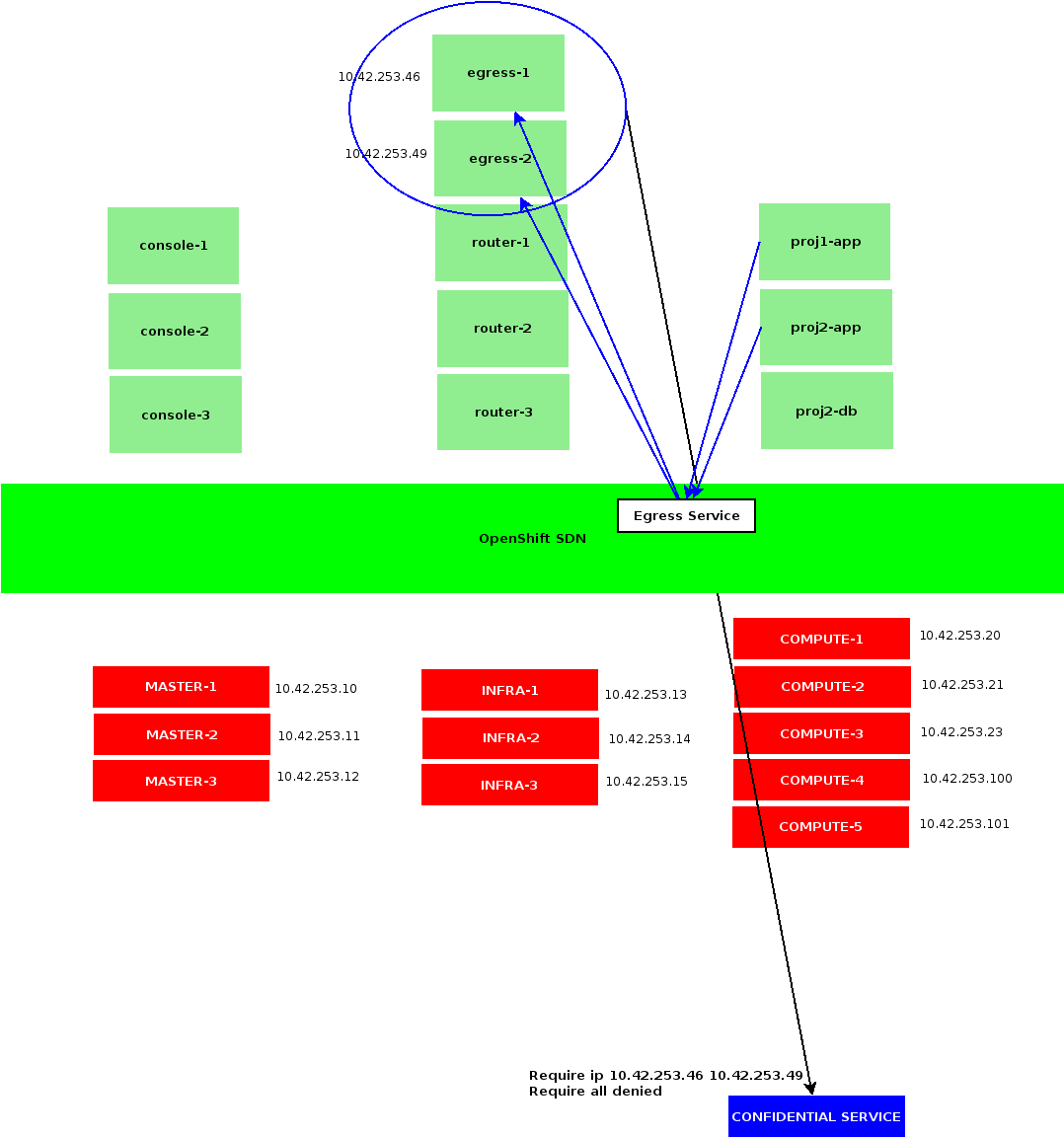
Note that the EGRESS_DESTINATION definition may include more than a single address, depending on the protocol and port queried, we could route those connections to distinct remotes:
env:
– name: EGRESS_DESTINATION
value: |
80 tcp 203.0.113.25
8080 tcp 203.0.113.26 80
8443 tcp 203.0.113.26 443
203.0.113.27
That snippet would ensure that connections to our router pod on TCP port 80 would be sent to a first remote address, while those to 8080 and 8443 are translated to ports 80 and 443 respectively of a second address, and any other traffic sent to a third remote address.
We could very well set these into a ConfigMap, to eventually include from our Pods configuration, ensuring consistency among a set of routers.
Obviously from OpenShift containers point of view, instead of connecting to our remote service, we would have to reach our Egress Router Service, which would in turn ensure proper forwarding of our requests.
Note that Redirect Egress Routers are limited to TCP and UDP traffic, while usually not recommended dealing with HTTP communications. That later case is best suited for the HTTP Proxy Egress Routers, relying on Squid.
Although very similar to Redirect Egress Routers, the HTTP Proxy would not set an EGRESS_DESTINATION environment variable on its init containers, and would instead pass an EGRESS_HTTP_PROXY_DESTINATION to the main container, such as:
$ cat <<EOF >egress-http.yml
apiVersion: v1
kind: ReplicationController
metadata:
name: egress-http
spec:
replicas: 1
selector:
name: egress-http
template:
metadata:
name: egress-http
labels:
name: egress-http
annotations:
pod.network.openshift.io/assign-macvlan: “true”
spec:
initContainers:
– name: egress-demo-init
image: openshift/origin-egress-router
env:
– name: EGRESS_SOURCE
value: 10.42.253.43
– name: EGRESS_GATEWAY
value: 10.42.253.1
– name: EGRESS_ROUTER_MODE
value: http-proxy
securityContext:
privileged: true
serviceAccountName: egress-init
containers:
– name: egress-demo-proxy
env:
– name: EGRESS_HTTP_PROXY_DESTINATION
value: |
!perdu.com
!*.perdu.com
!10.42.253.0/24
*
image: openshift/origin-egress-http-proxy
nodeSelector:
node-role.kubernetes.io/infra: “true”
serviceAccountName: egress-init
EOF
$ oc create -f egress-http.yml
Note the EGRESS_HTTP_PROXY_DESTINATION definition allows us to deny access to specific resources, such as perdu.com and its subdomain or an arbitrary private subnet, while we would allow any other communication with a wildcard.
By default, the Egress HTTP Proxy image listens on TCP port 8080, which allows us to create a service such as the following:
$ oc create service –name egress-http –namespace egress-routers –port=8080 –selector=egress-http
And eventually use that service from other OpenShift containers, based on environment variable proper definition:
$ oc rsh -n too jenkins-1-xyz
sh-4.2$ $ https_proxy=http://egress-http.egress-routers.svc:8080 http_proxy=http://egress-http.egress-routers.svc:8080/ curl -vfsL http://free.fr -o /dev/null
[… 200 OK …]
sh-4.2$ https_proxy=http://egress-http.egress-routers.svc:8080 http_proxy=http://egress-http.egress-routers.svc:8080/ curl -vfsL http://perdu.com -o /dev/null
[… 403 forbidden …]
As for our Redirect Egress Router, running tcpdump on our gateway would confirm traffic is properly NAT-ed:
# tcpdump -vvni vlan5 host 10.42.253.43
[…]
12:11:37.385219 212.27.48.10.443 > 10.42.253.43.55906: . [bad tcp cksum b96! -> 9b9f] 3563:3563(0) ack 446 win 30016 [tos 0x4] (ttl 63, id 1503, len 40)
12:11:37.385332 212.27.48.10.443 > 10.42.253.43.55906: F [bad tcp cksum b96! -> 9ba0] 3562:3562(0) ack 445 win 30016 [tos 0x4] (ttl 63, id 40993, len 40)
12:11:37.385608 10.42.253.43.55908 > 212.27.48.10.443: . [tcp sum ok] 472:472(0) ack 59942 win 64800 (DF) (ttl 64, id 1694, len 40)
12:11:37.385612 10.42.253.43.55906 > 212.27.48.10.443: . [tcp sum ok] 446:446(0) ack 3563 win 40320 (DF) (ttl 64, id 1695, len 40)
While our router ARP table would show records similar to Redirect Egress Router ones:
# arp -na | grep 10.42.253.43
10.42.253.43 d2:87:15:45:1c:28 vlan5 18m52s
Depending on security requirements and the kind of service we want to query, OpenShift is pretty flexible. Although the above configurations do not represent an exhaustive view of existing implementations, we did cover the most basic use cases from OpenShift documentations, which are more likely to remain supported.
Whenever possible, using namespace-scoped IPs seems to be easier, as it would not rely on any other service than OpenShift SDN applying proper routing and NAT-ing. Try to offer with several IPs per namespaces, allowing for quick failover, should a node become unavailable.
If port-based filtering is required, then Redirect Routers are more likely to satisfy, although deploying at least two Pods, using two distinct Egress IPs and node selectors would be recommended, as well as sharing a ConfigMap defining outbound routing.
Similarly, HTTP Proxy Routers would be recommended proxying HTTP traffic, as it would not require anything else than setting a few environment variables and ensuring our runtime does observe environment-based proxy configuration.