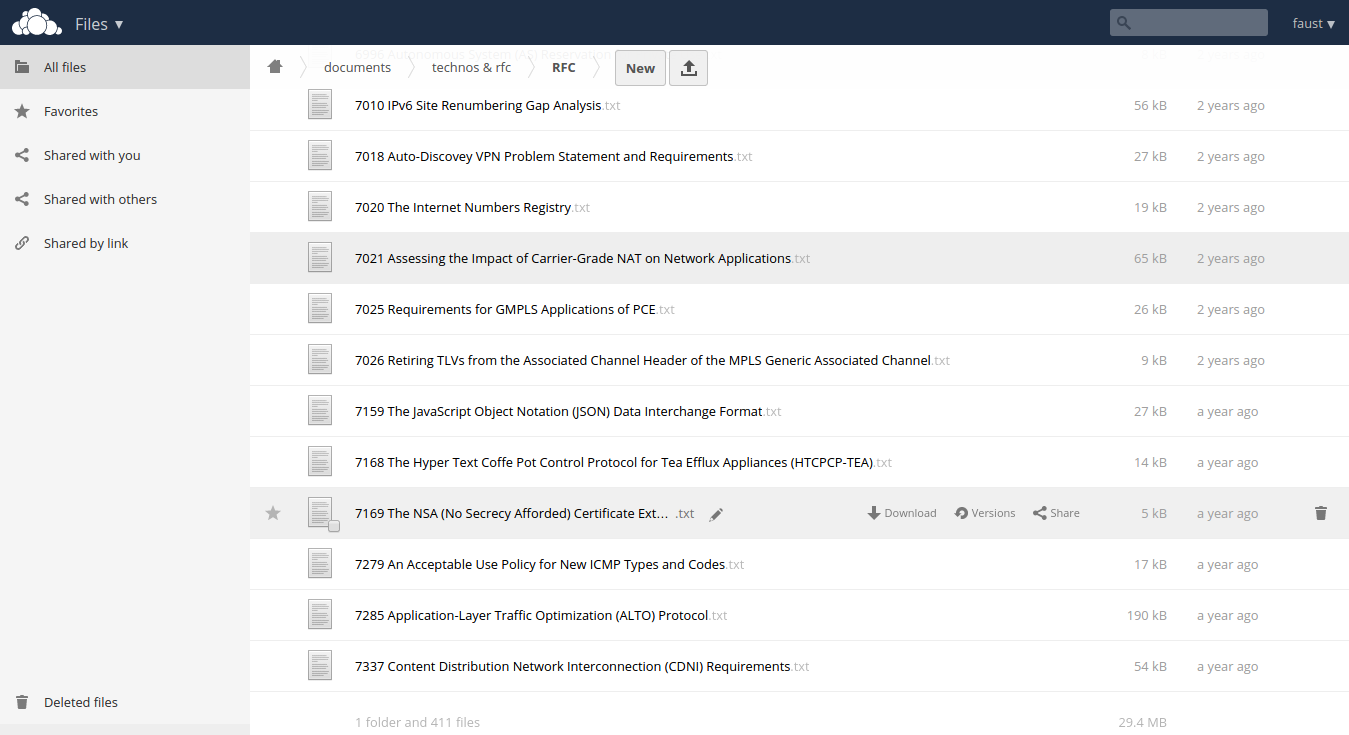
Munin is a popular supervision solution mostly based on perl.
As of most supervision and monitoring solution, munin relies on an agent you would install on hosts to track metrics from, and a server gathering metrics and serving them via CGI, generating graphics from collected data.
As of most supervision and monitoring solutions, munin uses loadable probes (plugins) to extract metrics.
The server side consists of a crontab. Iterating on all your hosts, it would list and execute all available probes, store the results into RRD.
Over thousand hosts, you may need to export munin working root to some tmpfs storage, adding a crontab to regularly rsync the content from this tmpfs to a persistent directory. In any case, hosting your filesystem on some SSD is relevant.
The main advantage of munin over its alternatives, I think, is its simplicity.
Main concurrent here being Collectd, which default web front end is particularly ugly and unpractical. And alternate front ends such as SickMuse are nice-looking, but still lack from simplicity, while some require excessively redundant configuration before being able to present something comparable to munin, in terms of relevance and efficiency.
It is also very easy, to implement your own probes. From scripts to binaries, with a simple way to set contextual variables – evaluated when the plugin name matches the context expression – and requiring a single declaration on the server to collect all metrics served by a node: I don’t know of any supervision solution easier to deploy. And to incorporate to your orchestration infrastructure.
Finally, debugging probes is conceptually easy: all you need is telnet.
muninone:~# telnet 10.42.242.98 4949
Trying 10.42.242.98...
Connected to 10.42.242.98.
Escape character is '^]'.
# munin node at cronos.adm.intra.unetresgrossebite.com
list
cpu df load memory ntp_kernel_err ntp_kernel_pll_freq ntp_kernel_pll_off open_files processes users vmstat
fetch cpu
user.value 3337308
nice.value 39168
system.value 13389003
interrupt.value 6679408
idle.value 701005749
.
quit
Connection closed by foreign host.
muninone:~#
Here is a bunch of plugins I use, that you won’t find in default installations. Most of them being copied from public repositories such as github.
Let’s introduce the few probes I wrote, starting with pool_. You may use it to wrap any munin probe. Its main advantage being it consists on a single cat, it answers quickly, and prevent you from generating discontinuous graphics.
I used it in conjunction with the esx_ probe (found somewhere / patched, mostly not mine), which may take several seconds to complete. When a probe takes time to answer, munin times out, discarding data. Using a crontab pooling and keeping your metrics to temporary files independently from munin traditional metrics retrieval process, and using the pool_ probe to present these temporary file is a way to deal with these probes, requiring unusual processing time.
Less relevant, the freebox_ probe, for Freebox V5 (inspired by a similar probe, dealing with Freebox V6):
# munin node at cronos.adm.intra.unetresgrossebite.com
fetch freebox_atm
atm_down.value 6261
atm_up.value 1025
.
fetch freebox_attenuation
attenuation_down.value 44.00
attenuation_up.value 24.80
.
fetch freebox_snr
snr_down.value 6.40
snr_up.value 7.20
.
fetch freebox_status
status.value 1
.
fetch freebox_uptime
uptime.value 131.73
.