Following up on a previous post introducing BlueMind, today we’ll focus on good practices (OpenDKIM, SPF, DMARC, ADSP, Spamassassin, firewalling) setting up their last available release (3.5.2) – and mail servers in general – while migrating my former setup (3.14).
A first requirement to ease up creating mailboxes, and manipulating passwords during the migration process, would be for your user accounts and mailing lists to be imported from some LDAP backend.
Assuming you do have a LDAP server, then you will need to create some service account in there, so BlueMind can bind. That account should have read access to your userPassword, pwdAccountLockedTime, entryUUID, entryDN, createTimestamp, modifyTimestamp and shadowLastChange attributes (assuming these do exist on your schema).
If you also want to configure distribution lists from LDAP groups, then you may want to load the dyngroup schema.
Another key to migrating your mail server would be to duplicate messages from one backend to another. Granted that your mailboxes already exist on both side, that some IMAP service is running on both sides, and that you can temporarily force your users password: then a tool you should consider is ImapSync. ImapSync can run for days, duplicate billions of mails, in thousands of folders, … Its simplicity is its strength.
Ideally, we would setup our new mail server without moving our MXs yet. The first ImapSync run could take days to complete. From there, next runs would only duplicate new messages and should go way faster: you may consider re-routing new messages to your new servers, continuing to run ImapSync until your former server stops receiving messages.
To give you an idea, my current setup involves less than 20 users, a little under 1.500.000 messages in about 400 folders, using around 30G of disk space. The initial ImapSync job ran for about 48 hours, the 3 next passes ran for less than one hour each.
A few years back, I did something similar involving a lot more mailboxes: in such cases, having some frontal postfix, routing messages to either one of your former and newer backend depending on the mailbox you’re reaching could be a big help in progressively migrating users from one to the other.
Now let’s dive into BlueMind configuration. We won’t cover the setup tasks as you’ll find these in BlueMind documentation.
Assuming you managed to install BlueMind, and that your users base is stored in some LDAP, make sure to install BlueMind LDAP import plugin:
apt-get install bm-plugin-admin-console-ldap-import bm-plugin-core-ldap-import
Note that if you were used to previous BlueMind releases, you will now need to grant each user with their accesses to your BlueMind services, including the webmail. By default, a newly created user account may only access its settings.
The management console would allow you to grant such permissions, there’s a lot of new stuff in this new release: multiple calendars per user, external calendars support, large files handling detached from webmail, …
The first thing we will configure is some firewall.
Note that Blue-Mind recommend to setup their service behind some kind of router, avoid exposing your instance directly to the Internet. Which is a good practice hosting pretty much everything anyway. Even though, you may want to setup some firewall.
Note that having your firewall up and running may lead to BlueMind installation script failing to complete: make sure to keep it down until you’re done with BlueMind installer.
On Debian, you may find the Firehol package to provide with an easy-to-configure firewall.
The service you would need to open for public access being smtp (TCP:25), http (TCP:80), imap (TCP:143), https (TCP:443), smtps (TCP:465), submission (TCP:587) and imaps (TCP:993).
Assuming firehol, your configuration would look like this:
mgt_ips=”1.2.3.4/32 2.3.4.5/32″
interface eth0 WAN
protection strong
server smtp accept
server http accept
server imap accept
server https accept
server smtps accept
server submission accept
server imaps accept
server custom openssh “tcp/1234” default accept src “$mgt_ips”
server custom munin “tcp/4949” default accept src “$mgt_ips”
server custom nrpe “tcp/5666” default accept src “$mgt_ips”
client all accept
You may then restart your firewall. To be safe, you could restart BlueMind as well.
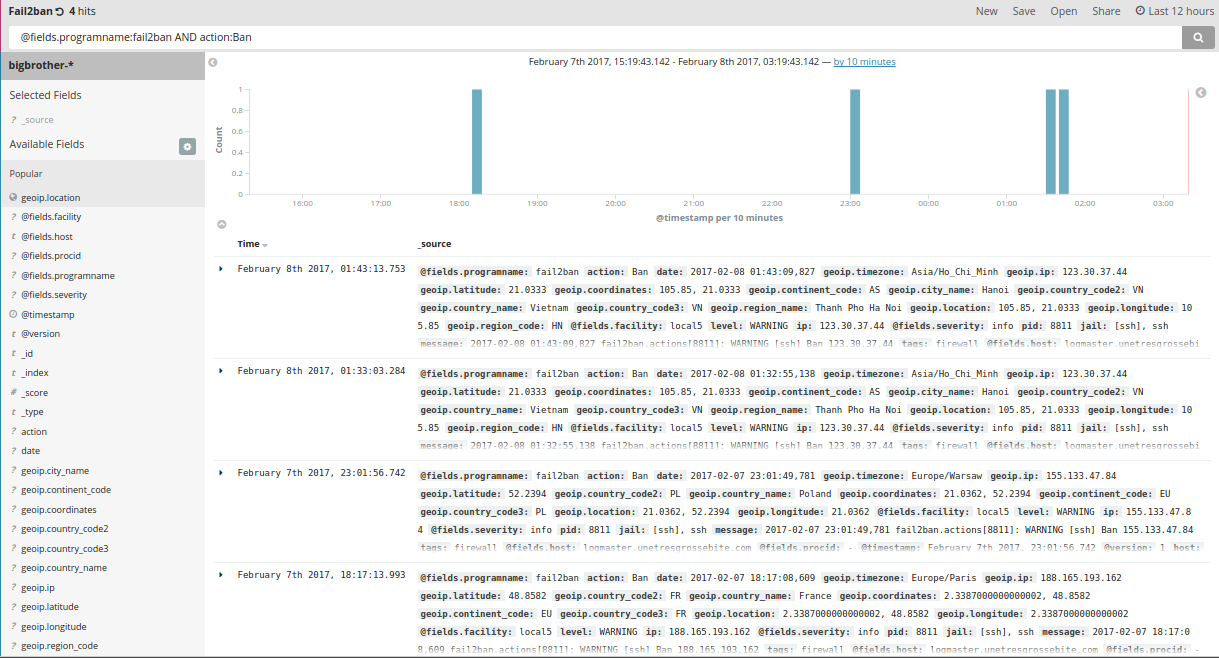
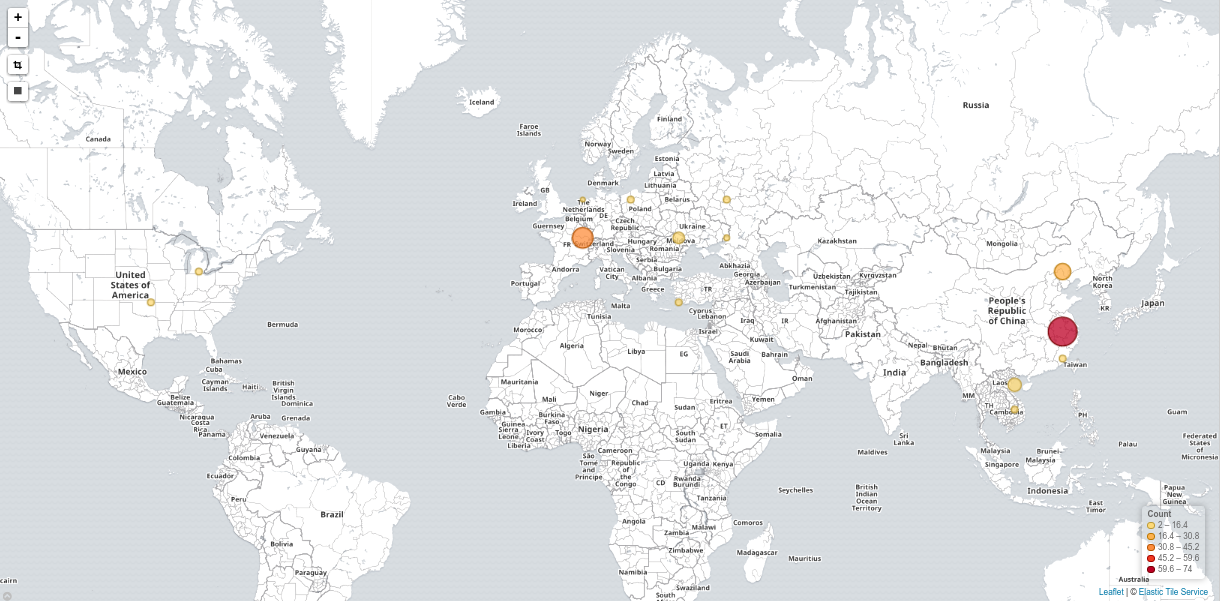
Optionally, you may want to use something like Fail2ban, also available on Debian. You may not be able to track all abusive accesses, although you could lock out SMTP authentication brute-forces at the very least, which is still relevant.
Note that BlueMind also provides with a plugin you could install from the packages cache extracted during BlueMind installation:
apt-get install bm-plugin-core-password-bruteforce
The second thing we would do is to install some valid certificate. These days, services like LetsEncrypt would issue free x509 certificates.
Still assuming Debian, a LetsEncrypt client is available in jessie-backports: certbot. This client would either need access to some directory served by your webserver, or would need to bind on your TCP port 443, so that LetsEncrypt may validate the common name you are requesting actually routes back to the server issuing this request. In the later case, we would do something like this:
# certbot certonly –standalone –text –email me@example.com –agree-tos –domain mail.example.com –renew-by-default
Having figured out how you’ll generate your certificate, we will now want to configure BlueMind services loading it in place of the self-signed one generated during installation:
# cp -p /etc/ssl/certs/bm_cert.pem /root/bm_cert.pem.orig
# cat /etc/letsencrypt/live/$CN/privkey.pem /etc/letsencrypt/live/$CN/fullchain.pem >/etc/ssl/certs/bm_cert.pem
Additionally, you will want to edit postfix configuration using LetsEncrypt certificate chain. In /etc/postfix/main.cf, look for smtpd_tls_CAfile and set it to /etc/letsencrypt/live/$CN/chain.pem.
You may now reload or restart postfix (smtps) and bm-nginx (both https & imaps).
Note that LetsEncrypt certificates are valid for 3 months. You’ll probably want to install some cron job renewing your certificate, updating /etc/ssl/certs/bm_cert.pem then reloading postfix and bm-nginx.
The next thing we would configure is OpenDKIM signing our outbound messages and validating signatures of inbound messages.
Debian has some opendkim package embedding everything you’ll need on a mail relay. Generating keys, you will also need to install opendkim-tools.
Create some directory layout and your keys:
# cd /etc
# mkdir dkim.d
# cd dkim.d
# mkdir keys keys/example1.com keys/example2.com keys/exampleN.com
# for d in example1 example2 exampleN; do \
( cd keys/$d.com; opendkim-genkey -r -d $d.com ); done
# chmod 0640 */default.private
# chown root:opendkim */default.private
In each of /etc/dkim.d/keys subdir, you will find a default.txt file that contains the DNS record you should add to the corresponding zone. Its content would look like the following:
default._domainkey IN TXT “v=DKIM1; k=rsa; p=PUBLICKEYDATA”
You should have these DNS records ready prior to having configured Postfix signing your messages.
Having generated our keys, we still need to configure OpenDKIM signing messages. On Debian, the main configuration is /etc/opendkim.conf, and should contain something like this:
Syslog yes
UMask 002
OversignHeaders From
KeyTable /etc/dkim.d/KeyTable
SigningTable /etc/dkim.d/SigningTable
ExternalIgnoreList /etc/dkim.d/TrustedHosts
InternalHosts /etc/dkim.d/TrustedHosts
You would need to create the 3 files we’re referring to in there, the first one being /etc/dkim.d/KeyTable:
default._domainkey.example1.com example1.com:default:/etc/dkim.d/keys/example1.com/default.private
default._domainkey.example2.com example2.com:default:/etc/dkim.d/keys/example2.com/default.private
default._domainkey.exampleN.com exampleN.com:default:/etc/dkim.d/keys/exampleN.com/default.private
The second one is /etc/dkim.d/SigningTable and would contain something like this:
example1.com default._domainkey.example1.com
example2.com default._domainkey.example2.com
exampleN.com default._domainkey.exampleN.com
And the last one, /etc/dkim.d/TrustedHosts would contain a list of the subnets we should sign messages for, such as
1.2.3.4/32
2.3.4.5/32
127.0.0.1
localhost
Now, let’s ensure OpenDKIM would start on boot, editing /etc/default/opendkim with following:
DAEMON_OPTS=
SOCKET=”inet:12345@localhost”
Having started OpenDKIM and made sure the service is properly listening on TCP:12345, you may now configure Postfix relaying its messages to OpenDKIM. Edit your /etc/postfix/main.cf adding the following:
milter_default_action = accept
smtpd_milters = inet:localhost:12345
non_smtpd_milters = inet:localhost:12345
Restart Postfix, make sure mail delivery works. Assuming you can already send outbound messages, make sure your DKIM signature appears to be valid for other mail providers (an obvious one being gmail).
Next, we’ll configure SPF validation of inbound messages.
On Debian, you would need to install postfix-policyd-spf-perl.
Let’s edit /etc/postfix/master.cf, adding a service validating inbound messages matches sender’s domain SPF policy:
spfcheck unix – n n – 0 spawn
user=policyd-spf argv=/usr/sbin/postfix-policyd-spf-perl
Next, edit /etc/postfix/main.cf, look for smtpd_recipient_restrictions. The last directive should be a reject_unauth_destination, and should precede the policy check we want to add:
smtpd_recipient_restrictions=permit_sasl_authenticated,
permit_mynetworks,reject_unauth_destination,
check_policy_service unix:private/policyd-spf
Restart Postfix, make sure you can still properly receive messages. Checked messages should now include some Received-SPF header.
Finally, we’ll configure SPAM checks and Spamassassin database training.
On Debian, you’ll need to install spamassassin.
Let’s edit /etc/spamassassin/local.cf defining a couple trusted IPs, and configuring Spamassassin to rewrite the subject for messages detected as SPAM:
rewrite_header Subject [ SPAM _SCORE_ ]
trusted_networks 1.2.3.4/32 2.3.4.5/32
score ALL_TRUSTED -5
required_score 2.0
use_bayes 1
bayes_auto_learn 1
bayes_path /root/.spamassassin/bayes
bayes_ignore_header X-Spam-Status
bayes_ignore_header X-Spam-Flag
ifplugin Mail::SpamAssassin::Plugin::Shortcircuit
shortcircuit ALL_TRUSTED on
shortcircuit BAYES_99 spam
shortcircuit BAYES_00 ham
endif
Configure Spamassassin service defaults in /etc/default/spamassassin:
CRON=1
ENABLED=1
NICE=”–nicelevel 15″
OPTIONS=”–create-prefs –max-children 5 -H /var/log/spamassassin -s /var/log/spamassassin/spamd.log”
PIDFILE=/var/run/spamd.pid
Make sure /root/.spamassassin and /var/log/spamassassin both exist.
Now let’s configure Spamassassin to lear from BlueMind SPAM folders content, create or edit /etc/spamassassin/sa-learn-cyrus.conf with the following content:
[global]
tmp_dir = /tmp
lock_file = /var/lock/sa-learn-cyrus.lock
verbose = 1
simulate = no
log_with_tag = yes
[mailbox]
include_list = ”
include_regexp = ‘.*’
exclude_list = ”
exclude_regexp = ”
spam_folder = ‘Junk’
ham_folder = ‘Inbox’
remove_spam = yes
remove_ham = no
[sa]
debug = no
site_config_path = /etc/spamassassin
learn_cmd = /usr/bin/sa-learn
bayes_storage = berkely
prefs_file = /etc/spamassassin/local.cf
fix_db_permissions = yes
user = mail
group = mail
sync_once = yes
virtual_config_dir = ”
[imap]
base_dir = /var/spool/cyrus/example_com/domain/e/example.com/
initial_letter = yes
domains = ”
unixhierarchysep = no
purge_cmd = /usr/lib/cyrus/bin/ipurge
user = cyrus
Look out for sa-learn-cyrus script. Note that Debian provides with a package with that name, that would pull cyrus as a dependency – which is definitely something you want on a BlueMind server.
Run this script to train Spamassassin from the messages in your Inboxes and Junk folders. Eventually, you could want to install some cron job.
Start or restart Spamassassin service. Now, let’s configure Postfix piping its messages to Spamassassin. Edit /etc/postfix/master.cf, add the following service:
spamassassin unix – n n – – pipe
user=debian-spamd argv=/usr/bin/spamc -f -e
/usr/sbin/sendmail -oi -f ${sender} ${recipient}
Still in /etc/postfix/master.cf, locate the smtp service, and add a content_filter option pointing to our spamassassin service:
smtp inet n – n – – smtpd
-o content_filter=spamassassin
Restart Postfix. Sending or receiving messages, you should read about spamd in /var/log/mail.log. Moreover, a X-Spam-Checker-Version header should show in your messages.
Prior to migrating your messages, make sure to mount /var/spool/cyrus on a separate device, and /var/backups/bluemind on some NFS share, LUN device, sshfs, …. something remote, ideally.
Your /tmp may be mounted from tmpfs, and could use the nosuid and nodev options – although you can not set noexec.
Assuming you have some monitoring system running: make sure to keep an eye on mail queues, smtp service availability or disk space among others, …
Being done migrating your setup, the last touch would be to set proper SPF, ADSP and DMARC policies (DNS records).
Your SPF record defines which IPs may issue mail on behalf of your domain. Usually, you just want to allow your MXs (mx). Maybe you’ll want to trust some additional record, … And deny everyone else (-all). Final record could look like this:
@ IN TXT “v=spf1 mx a:non-mx-sender.example.com -all”
Having defined your SPF policy, and assuming you properly configured DKIM signing, while corresponding public key is published in your DNS, then you may consider defining some DMARC policy as well.
@ IN TXT v=DMARC1; p=quarantine; pct=100; rua=mailto:postmaster@example.com
And ADSP:
_adsp._domainkey IN TXT “dkim=all;”
… and that’s pretty much it. The rest’s up to you, and would probably be doable from BlueMind administration console.